Pengantar
Pencocokan string adalah subjek yang sangat penting dalam domain yang lebih luas dari pengolahan teks. algoritma pencocokan string adalah komponen dasar yang digunakan dalam implementasi software praktis yang ada di bawah sistem operasi. Selain itu, mereka menekankan metode pemrograman yang berfungsi sebagai paradigma di bidang lain dari ilmu komputer (sistem atau desain perangkat lunak). Akhirnya, mereka juga memainkan peran penting dalam ilmu komputer teoritis dengan memberikan masalah yang menantang.
Walaupun data hafal dengan berbagai cara, teks tetap bentuk utama untuk bertukar informasi. Hal ini terutama jelas dalam literatur atau linguistik dimana data terdiri dari corpus besar dan kamus. Ini berlaku juga untuk ilmu komputer di mana sejumlah besar data yang disimpan dalam file linear. Dan ini juga terjadi, misalnya, dalam biologi molekuler karena molekul biologis sering dapat diperkirakan sebagai urutan nukleotida atau asam amino. Selanjutnya, jumlah data yang tersedia di bidang ini cenderung dua kali lipat setiap delapan belas bulan. Ini adalah alasan mengapa algoritma harus efisien bahkan jika kecepatan dan kapasitas penyimpanan komputer meningkat secara teratur.
Pencocokan string terdiri dalam menemukan satu, atau lebih umum, semua kejadian dari string (lebih umum disebut pola ) dalam teks . Semua algoritma dalam output buku ini semua kejadian dari pola dalam teks. Pola ini dilambangkan dengan x = x [0 .. m -1]; panjangnya sama dengan m . Teks dilambangkan dengan y = y [0 .. n -1]; panjangnya sama dengan n .Kedua string adalah membangun lebih dari satu set terbatas karakter disebut sebuah alfabet dilambangkan dengan  dengan ukuran sama dengan
dengan ukuran sama dengan  .
.
Aplikasi memerlukan dua macam solusi tergantung pada string, pola atau teks, diberikan pertama. Algoritma berdasarkan penggunaan automata atau kombinasi sifat dari string biasanya diterapkan untuk preprocess pola dan memecahkan jenis pertama dari masalah. Gagasan indeks direalisasikan oleh pohon atau automata digunakan dalam jenis kedua solusi. Buku ini hanya akan menyelidiki algoritma jenis pertama.
Algoritma pencocokan string dari pekerjaan buku ini sebagai berikut. Mereka memindai teks dengan bantuan sebuah jendela yang berukuran umumnya sama dengan m . Mereka pertama kali menyelaraskan ujung kiri jendela dan teks, kemudian membandingkan karakter dari jendela dengan karakter dari pola - pekerjaan spesifik ini disebut upaya - dan setelah seluruh pertandingan dari pola atau setelah ketidakcocokan mereka bergeser tersebut jendela ke kanan. Mereka mengulangi prosedur yang sama lagi sampai akhir kanan jendela melampaui ujung kanan teks. Mekanisme ini biasanya disebut mekanisme sliding window . Kami mengaitkan setiap upaya dengan posisi j dalam teks ketika jendela diposisikan pada y [ j .. j + m-1 ].
Brute Force algoritma menempatkan semua kejadian x di y dalam waktu O ( mn ). Banyak perbaikan dari metode brute force dapat diklasifikasikan tergantung pada urutan mereka melakukan perbandingan antara karakter pola dan karakter teks et setiap upaya. Empat kategori timbul: cara yang paling alami untuk melakukan perbandingan adalah dari kiri ke kanan, yang merupakan arah membaca; melakukan perbandingan dari kanan ke kiri umumnya mengarah ke algoritma terbaik dalam praktek; yang terbaik batas teoritis tercapai bila perbandingan dilakukan dalam urutan tertentu; akhirnya terdapat beberapa algoritma yang urutan di mana perbandingan yang dilakukan adalah tidak relevan (seperti adalah algoritma brute force).
Dari kiri ke kanan
Hashing menyediakan metode sederhana yang menghindari jumlah kuadrat dari perbandingan karakter dalam kebanyakan situasi praktis, dan yang berjalan dalam waktu linier dengan asumsi probabilistik wajar. Telah diperkenalkan oleh Harrison dan kemudian sepenuhnya dianalisa dengan Karp dan Rabin .
Dengan asumsi bahwa panjang pola tidak lebih panjang dari ukuran memori-kata mesin, Pergeseran Atau algoritma adalah algoritma yang efisien untuk memecahkan masalah pencocokan string yang tepat dan menyesuaikan dengan mudah untuk berbagai masalah string yang cocok perkiraan.
Linear-waktu algoritma pencocokan string yang pertama adalah dari Morris dan Pratt . Ini telah diperbaiki oleh Knuth, Morris dan Pratt . Pencarian berperilaku seperti proses pengakuan oleh robot, dan karakter dari teks dibandingkan dengan karakter pola tidak lebih dari log 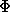 ( m 1) ( adalah rasio emas
( m 1) ( adalah rasio emas 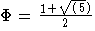 ). Hancart membuktikan bahwa keterlambatan ini dari algoritma terkait ditemukan oleh Simon membuat tidak lebih dari 1 + log 2 m perbandingan per karakter teks. Ketiga algoritma tampil paling banyak 2 n perbandingan karakter -1 teks dalam kasus terburuk.
). Hancart membuktikan bahwa keterlambatan ini dari algoritma terkait ditemukan oleh Simon membuat tidak lebih dari 1 + log 2 m perbandingan per karakter teks. Ketiga algoritma tampil paling banyak 2 n perbandingan karakter -1 teks dalam kasus terburuk.
Pencarian dengan Deterministic Finite Automaton melakukan persis n inspeksi karakter teks tetapi membutuhkan ruang tambahan di O ( m ). The Teruskan Dawg Matching algoritma melakukan persis jumlah yang sama dari inspeksi karakter teks menggunakan otomat akhiran dari pola.
Apostolico-Crochemore algoritma adalah algoritma sederhana yang melakukan  n perbandingan karakter teks dalam kasus terburuk.
n perbandingan karakter teks dalam kasus terburuk.
Algoritma Tidak Jadi Naif adalah algoritma yang sangat sederhana dengan kompleksitas waktu kasus kuadrat terburuk tetapi membutuhkan fase preprocessing dalam waktu yang konstan dan ruang dan sedikit sub-linear dalam kasus rata-rata.
Dari kanan ke kiri
Boyer-Moore algoritma dianggap sebagai algoritma pencocokan string yang paling efisien dalam aplikasi biasa. Sebuah versi sederhana dari itu (atau seluruh algoritma) sering diimplementasikan dalam teks editor untuk "mencari" dan perintah "pengganti". Cole membuktikan bahwa jumlah maksimum perbandingan karakter erat dibatasi oleh 3 n setelah preprocessing untuk pola non-periodik. Memiliki waktu kasus terburuk kuadrat untuk pola periodik.
Beberapa varian dari algoritma Boyer-Moore menghindari perilaku kuadrat nya. Solusi yang paling efisien dalam hal jumlah perbandingan simbol telah dirancang oleh Apostolico dan Giancarlo , Crochemore et alii ( Turbo BM ), dan Colussi ( Reverse Colussi ).
Hasil empiris menunjukkan bahwa variasi algoritma Boyer dan Moore yang dirancang oleh Minggu ( Pencarian Cepat ) dan algoritma berdasarkan otomat akhiran oleh Crochemore et alii ( Reverse Factor dan Turbo Reverse Factor ) yang paling efisien dalam praktek.
The Zhu dan Takaoka dan Berry-Ravindran algoritma adalah varian dari algoritma Boyer-Moore yang membutuhkan ruang ekstra di O ( 2 ).
Dalam urutan tertentu
Dua ruang yang optimal algoritma pencocokan string linear pertama adalah karena Galil-Seiferas dan Crochemore-Perrin ( Two Way algoritma). Mereka partisi pola dalam dua bagian, mereka pertama kali mencari bagian kanan dari pola dari kiri ke kanan dan kemudian jika ada ketidakcocokan terjadi mereka mencari bagian kiri.
Algoritma dari Colussi dan Galil-Giancarlo partisi set posisi pola menjadi dua himpunan bagian. Mereka pertama mencari karakter pola yang posisi berada di bagian pertama dari kiri ke kanan dan kemudian jika ada ketidakcocokan terjadi mereka mencari karakter yang tersisa dari kiri ke kanan. Algoritma Colussi merupakan perbaikan atas algoritma Knuth-Morris-Pratt dan melakukan paling n perbandingan karakter teks dalam kasus terburuk. Algoritma Galil-Giancarlo meningkatkan algoritma Colussi dalam satu kasus khusus yang memungkinkan untuk tampil di kebanyakan 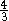 n perbandingan karakter teks dalam kasus terburuk.
n perbandingan karakter teks dalam kasus terburuk.
Minggu Optimal Mismatch dan Pergeseran Maksimal algoritma mengurutkan posisi pola menurut frekuensi karakter mereka dan pergeseran terkemuka mereka masing-masing.
Loncat Cari , KMP Lewati Cari dan Alpha Lewati Cari algoritma oleh Charras ( et alii ) menggunakan ember untuk menentukan posisi awal pada pola dalam teks.
Dalam urutan apapun
Horspool algoritma adalah varian dari Boyer-Moore algoritma, menggunakan salah satu dari fungsi pergeseran dan urutan di mana perbandingan karakter teks yang dilakukan adalah tidak relevan. Hal ini juga berlaku untuk semua varian lainnya seperti Pencarian Cepat Minggu, Tuned Boyer-Moore dari Hume dan Minggu, para Smith algoritma dan Raita algoritma.
Definisi
Kami akan mempertimbangkan pencarian praktis. Kami akan menganggap bahwa alfabet adalah himpunan kode ASCII atau bagian dari itu. Algoritma disajikan dalam bahasa pemrograman C, sehingga untuk sebuah kata w panjang 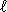 karakter yang w [0], ..., w [ -1] dan w [ ] terkandung karakter akhir khusus (karakter nol) yang tidak bisa terjadi di mana saja dalam setiap kata tapi pada akhirnya. Kedua kata pola dan teks berada di memori utama.
karakter yang w [0], ..., w [ -1] dan w [ ] terkandung karakter akhir khusus (karakter nol) yang tidak bisa terjadi di mana saja dalam setiap kata tapi pada akhirnya. Kedua kata pola dan teks berada di memori utama.
Mari kita memperkenalkan beberapa definisi.
Sebuah kata u adalah awalan dari kata w adalah terdapat kata v (mungkin kosong) sehingga w = uv .
Sebuah kata v adalah akhiran dari kata w adalah terdapat kata u (mungkin kosong) sehingga w = uv .
Sebuah kata z adalah substring atau subword atau faktor dari sebuah kata w adalah terdapat dua kata u dan v (mungkin kosong) sehingga w = uzv .
Integer p adalah periode dari kata w jika untuk saya , 0  i < m - p , w [ i ] = w [ i + p ]. Periode terkecil w disebut periode , itu dilambangkan dengan per ( w ).
i < m - p , w [ i ] = w [ i + p ]. Periode terkecil w disebut periode , itu dilambangkan dengan per ( w ).
Sebuah kata w panjang adalah periodik jika panjang periode nya terkecil lebih kecil atau sama dengan / 2, jika tidak non-periodik .
Sebuah kata w adalah dasar jika tidak dapat ditulis sebagai kekuatan kata lain: tidak ada ada kata z dan tidak ada bilangan bulat k sehingga w = z k .
Sebuah kata z adalah perbatasan dari kata w jika terdapat dua kata u dan v sehingga w = uz = ZV , z merupakan sebuah awalan dan akhiran dari w . Perhatikan bahwa dalam kasus ini | u | = | v | adalah periode w .
Kebalikan dari kata w panjang dilambangkan dengan w R adalah bayangan cermin dari w ; w R = w [ -1] w [ -2] ... w [1] w [0].
Sebuah Deterministic Finite Automaton (DFA) A adalah quadruple ( Q , q 0 , T , E ) dimana:
 |
Q adalah himpunan berhingga dari negara; |
| |
q 0 di Q adalah keadaan awal; |
| |
T , bagian dari Q , adalah himpunan negara terminal; |
| |
E, bagian dari ( Q .. Q ), adalah himpunan transisi. |
Bahasa L ( A ) didefinisikan oleh A adalah himpunan berikut:
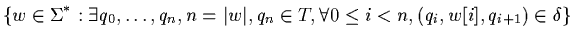
Untuk setiap algoritma pencocokan string yang tepat disajikan dalam buku ini pertama kami memberikan fitur utama, maka kami menjelaskan cara kerjanya sebelum memberikan kode C-nya.Setelah itu kita menunjukkan perilaku pada satu contoh di mana x = GCAGAGAG dan y = GCATCGCAGAGAGTATACAGTACG. Akhirnya kami memberikan daftar referensi di mana pembaca akan menemukan presentasi yang lebih rinci dan bukti dari algoritma. Pada setiap upaya, pertandingan yang terwujud dalam abu-abu terang sementara ketidaksesuaian ditampilkan dalam abu-abu gelap. Sejumlah menunjukkan urutan perbandingan karakter dilakukan kecuali untuk algoritma menggunakan automata mana jumlah mewakili negara mencapai setelah pemeriksaan karakter.
Pelaksanaan
Dalam buku ini, kita akan menggunakan alat klasik. Salah satunya adalah linked list integer. Ini akan didefinisikan di C sebagai berikut:
struct _cell{
int element;
struct _cell *next;
};
typedef struct _cell *List;
Struktur penting lain adalah automata dan automata khusus akhiran (lihat Bab 22 ). Pada dasarnya automata diarahkan grafik. Kami akan menggunakan antarmuka berikut untuk memanipulasi automata:
Graph newGraph(int v, int e); Graph newAutomaton(int v, int e); Graph newSuffixAutomaton(int v, int e); int newVertex(Graph g); int getInitial(Graph g); boolean isTerminal(Graph g, int v); void setTerminal(Graph g, int v); int getTarget(Graph g, int v, unsigned char c); void setTarget(Graph g, int v, unsigned char c, int t); int getSuffixLink(Graph g, int v); void setSuffixLink(Graph g, int v, int s); int getLength(Graph g, int v); void setLength(Graph g, int v, int ell); int getPosition(Graph g, int v); void setPosition(Graph g, int v, int p); int getShift(Graph g, int v, unsigned char c); void setShift(Graph g, int v, unsigned char c, int s); void copyVertex(Graph g, int target, int source);
Sebuah kemungkinan implementasi dari interface ini berikut.
struct _graph {
int vertexNumber,
edgeNumber,
vertexCounter,
initial,
*terminal,
*target,
*suffixLink,
*length,
*position,
*shift;
};
typedef struct _graph *Graph;
typedef int boolean;
#define UNDEFINED -1
/* returns a new data structure for
a graph with v vertices and e edges */
Graph newGraph(int v, int e) {
Graph g;
g = (Graph)calloc(1, sizeof(struct _graph));
if (g == NULL)
error("newGraph");
g->vertexNumber = v;
g->edgeNumber = e;
g->initial = 0;
g->vertexCounter = 1;
return(g);
}
/* returns a new data structure for
a automaton with v vertices and e edges */
Graph newAutomaton(int v, int e) {
Graph aut;
aut = newGraph(v, e);
aut->target = (int *)calloc(e, sizeof(int));
if (aut->target == NULL)
error("newAutomaton");
aut->terminal = (int *)calloc(v, sizeof(int));
if (aut->terminal == NULL)
error("newAutomaton");
return(aut);
}
/* returns a new data structure for
a suffix automaton with v vertices and e edges */
Graph newSuffixAutomaton(int v, int e) {
Graph aut;
aut = newAutomaton(v, e);
memset(aut->target, UNDEFINED, e*sizeof(int));
aut->suffixLink = (int *)calloc(v, sizeof(int));
if (aut->suffixLink == NULL)
error("newSuffixAutomaton");
aut->length = (int *)calloc(v, sizeof(int));
if (aut->length == NULL)
error("newSuffixAutomaton");
aut->position = (int *)calloc(v, sizeof(int));
if (aut->position == NULL)
error("newSuffixAutomaton");
aut->shift = (int *)calloc(e, sizeof(int));
if (aut->shift == NULL)
error("newSuffixAutomaton");
return(aut);
}
/* returns a new data structure for
a trie with v vertices and e edges */
Graph newTrie(int v, int e) {
Graph aut;
aut = newAutomaton(v, e);
memset(aut->target, UNDEFINED, e*sizeof(int));
aut->suffixLink = (int *)calloc(v, sizeof(int));
if (aut->suffixLink == NULL)
error("newTrie");
aut->length = (int *)calloc(v, sizeof(int));
if (aut->length == NULL)
error("newTrie");
aut->position = (int *)calloc(v, sizeof(int));
if (aut->position == NULL)
error("newTrie");
aut->shift = (int *)calloc(e, sizeof(int));
if (aut->shift == NULL)
error("newTrie");
return(aut);
}
/* returns a new vertex for graph g */
int newVertex(Graph g) {
if (g != NULL && g->vertexCounter <= g->vertexNumber)
return(g->vertexCounter++);
error("newVertex");
}
/* returns the initial vertex of graph g */
int getInitial(Graph g) {
if (g != NULL)
return(g->initial);
error("getInitial");
}
/* returns true if vertex v is terminal in graph g */
boolean isTerminal(Graph g, int v) {
if (g != NULL && g->terminal != NULL &&
v < g->vertexNumber)
return(g->terminal[v]);
error("isTerminal");
}
/* set vertex v to be terminal in graph g */
void setTerminal(Graph g, int v) {
if (g != NULL && g->terminal != NULL &&
v < g->vertexNumber)
g->terminal[v] = 1;
else
error("isTerminal");
}
/* returns the target of edge from vertex v
labelled by character c in graph g */
int getTarget(Graph g, int v, unsigned char c) {
if (g != NULL && g->target != NULL &&
v < g->vertexNumber && v*c < g->edgeNumber)
return(g->target[v*(g->edgeNumber/g->vertexNumber) +
c]);
error("getTarget");
}
/* add the edge from vertex v to vertex t
labelled by character c in graph g */
void setTarget(Graph g, int v, unsigned char c, int t) {
if (g != NULL && g->target != NULL &&
v < g->vertexNumber &&
v*c <= g->edgeNumber && t < g->vertexNumber)
g->target[v*(g->edgeNumber/g->vertexNumber) + c] = t;
else
error("setTarget");
}
/* returns the suffix link of vertex v in graph g */
int getSuffixLink(Graph g, int v) {
if (g != NULL && g->suffixLink != NULL &&
v < g->vertexNumber)
return(g->suffixLink[v]);
error("getSuffixLink");
}
/* set the suffix link of vertex v
to vertex s in graph g */
void setSuffixLink(Graph g, int v, int s) {
if (g != NULL && g->suffixLink != NULL &&
v < g->vertexNumber && s < g->vertexNumber)
g->suffixLink[v] = s;
else
error("setSuffixLink");
}
/* returns the length of vertex v in graph g */
int getLength(Graph g, int v) {
if (g != NULL && g->length != NULL &&
v < g->vertexNumber)
return(g->length[v]);
error("getLength");
}
/* set the length of vertex v to integer ell in graph g */
void setLength(Graph g, int v, int ell) {
if (g != NULL && g->length != NULL &&
v < g->vertexNumber)
g->length[v] = ell;
else
error("setLength");
}
/* returns the position of vertex v in graph g */
int getPosition(Graph g, int v) {
if (g != NULL && g->position != NULL &&
v < g->vertexNumber)
return(g->position[v]);
error("getPosition");
}
/* set the length of vertex v to integer ell in graph g */
void setPosition(Graph g, int v, int p) {
if (g != NULL && g->position != NULL &&
v < g->vertexNumber)
g->position[v] = p;
else
error("setPosition");
}
/* returns the shift of the edge from vertex v
labelled by character c in graph g */
int getShift(Graph g, int v, unsigned char c) {
if (g != NULL && g->shift != NULL &&
v < g->vertexNumber && v*c < g->edgeNumber)
return(g->shift[v*(g->edgeNumber/g->vertexNumber) +
c]);
error("getShift");
}
/* set the shift of the edge from vertex v
labelled by character c to integer s in graph g */
void setShift(Graph g, int v, unsigned char c, int s) {
if (g != NULL && g->shift != NULL &&
v < g->vertexNumber && v*c <= g->edgeNumber)
g->shift[v*(g->edgeNumber/g->vertexNumber) + c] = s;
else
error("setShift");
}
/* copies all the characteristics of vertex source
to vertex target in graph g */
void copyVertex(Graph g, int target, int source) {
if (g != NULL && target < g->vertexNumber &&
source < g->vertexNumber) {
if (g->target != NULL)
memcpy(g->target +
target*(g->edgeNumber/g->vertexNumber),
g->target +
source*(g->edgeNumber/g->vertexNumber),
(g->edgeNumber/g->vertexNumber)*
sizeof(int));
if (g->shift != NULL)
memcpy(g->shift +
target*(g->edgeNumber/g->vertexNumber),
g->shift +
source*(g->edgeNumber/g->vertexNumber),
g->edgeNumber/g->vertexNumber)*
sizeof(int));
if (g->terminal != NULL)
g->terminal[target] = g->terminal[source];
if (g->suffixLink != NULL)
g->suffixLink[target] = g->suffixLink[source];
if (g->length != NULL)
g->length[target] = g->length[source];
if (g->position != NULL)
g->position[target] = g->position[source];
}
else
error("copyVertex");
}
