Tutorial di Internet Pemantauan & PingER at SLAC
Les Cottrell , Warren Matthews dan Connie Logg, Dibuat Januari 1996; Perbarui terakhir: Decembeer 1, 2014. Halaman rumah IEPM | Pinger | Pinger Detil Laporan | Pinger Peta Situs | tutorialBekerja sebagian didanai oleh DOE / MICS Kerja Lapangan Hibah Internet End-to-end Monitoring Kinerja (IEPM) .
Pengantar
Untuk memberikan harapan yang lebih baik dari kinerja jaringan antara situs yang SLAC bekerja sama dengan, pada Mei 1996 proyek Pinger (dimulai pada Janary 1995) dipantau sekitar 100 host di seluruh dunia dari SLAC. Sejak tahun 2000, penekanannya lebih pada pengukuran Digital Divide. Saat ini (April 2007) ada lebih dari 35 Situs Pemantauan , lebih dari 600 situs remote yang dipantau di lebih dari 150 negara (yang mengandung lebih dari 99% dari dunia Internet populasi terhubung) dan pasangan lebih dari 8.000 monitor situs remote-situs disertakan. Rincian lebih lanjut tentang penyebaran Pinger dapat ditemukan di pinger Deployment dan ada peta situs.Mekanisme
Mekanisme utama yang digunakan adalah Internet Control Message Protocol (ICMP) mekanisme Echo, juga dikenal sebagai fasilitas Ping. Hal ini memungkinkan Anda untuk mengirim paket dari panjang pengguna yang dipilih untuk node remote dan memiliki itu bergema kembali. Saat itu biasanya datang pra-instal pada hampir semua platform, sehingga tidak ada yang diinstal pada klien. Server (yaitu reponder echo) berjalan pada prioritas tinggi (misalnya di kernel Unix) dan lebih mungkin untuk memberikan ukuran yang baik dari kinerja jaringan dari aplikasi pengguna. Hal ini sangat sederhana dalam kebutuhan bandwidth jaringan (~ 100 bit per detik per monitoring-remote host-pasangan untuk cara kita menggunakannya).Metode pengukuran
Dalam proyek Pinger, setiap 30 menit cron dari pemantauan simpul (Pengukuran Titik - MP), kita ping satu set node jauh dengan 11 ping dari 100 byte masing-masing (termasuk 8 ICMP byte tetapi tidak header IP). Ping dipisahkan oleh setidaknya satu detik, dan default ping batas waktu 20 detik digunakan. Ping pertama dibuang (itu diduga menjadi lambat karena itu priming cache dll (Martin Horneffer di "http://www.advanced.org/IPPM/archive.2/0246.html" melaporkan bahwa menggunakan UDP paket -echo dan antar-kedatangan-waktu sekitar 12,5 detik paket pertama memakan waktu sekitar 20% lebih banyak waktu untuk kembali)). Minimum / Rata-rata / maksimum RTT untuk setiap set 10 ping dicatat. Ini diulang selama sepuluh ping dari 1000 byte data. Penggunaan dua ukuran ping paket memungkinkan kita untuk membuat estimasi dari kecepatan data ping dan juga untuk tempat perilaku yang berbeda antara paket kecil dan besar (misalnya tingkat membatasi). Lihat Big vs paket kecil , waktu pengukuran ping untuk lebih jelasnya. Secara umum RTT sebanding dengan l (di mana l adalah panjang paket) sampai dengan ukuran datagram maksimum (biasanya 1472 byte termasuk 8 ICMP bytes). Perilaku di luar itu tidak terdefinisi (beberapa jaringan fragmen paket, yang lain menjatuhkan mereka). Dokumentasi pada script pengukuran direkomendasikan yang berjalan di setiap situs monitoring tersedia. Ping kali respon yang diplot untuk setiap setengah jam untuk setiap node. Ini terutama digunakan untuk trouble shooting (misalnya melihat apakah itu mendapat dramatis buruk dalam beberapa jam terakhir).Set host remote untuk ping disediakan oleh sebuah file yang bernama pinger.xml (untuk lebih lanjut tentang ini lihat dokumentasi pinger2.pl ). File ini terdiri dari dua bagian: Beacon host yang secara otomatis ditarik setiap hari dari SLAC dan dipantau oleh semua anggota parlemen; host lain yang menarik khusus untuk administrator MP. The Beacon host (dan host tertentu dipantau oleh SLAC MP) disimpan dalam database Oracle yang berisi nama, alamat IP, situs, nama panggilan, lokasi, hubungi dll Daftar Beacon (dan daftar host tertentu untuk SLAC) dan copy dari database, dalam format untuk menyederhanakan akses Perl untuk script analisis, secara otomatis dihasilkan dari database setiap hari.
Pengumpulan data
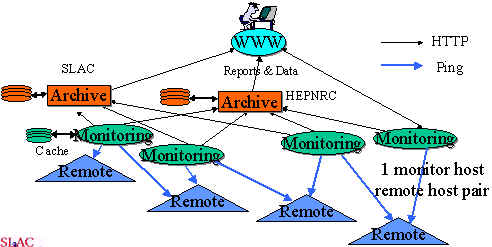
Arsitektur pemantauan meliputi 3 komponen:- Situs pemantauan jarak jauh. Ini hanya menyediakan remote-host yang pasif dengan tepat kebutuhan .
- Situs monitoring. The alat monitoring pinger harus diinstal dan dikonfigurasi pada host di masing-masing situs. Juga data ping yang dikumpulkan kebutuhan yang akan dibuat tersedia untuk host arsip melalui HyperText tansport Protocol (HTTP) (yaitu harus ada server Web untuk menyediakan data pada permintaan melalui Web). Ada juga alat Pinger untuk mengaktifkan situs monitoring untuk dapat memberikan analisis jangka pendek dan laporan data yang telah di cache lokal.
- Arsip dan analisis situs. Harus ada setidaknya satu masing-masing untuk setiap proyek Pinger. Situs arsip dan analisis mungkin terletak di satu situs, atau bahkan sebuah host atau mereka dapat dipisahkan. Proyek Pinger memiliki dua situs tersebut, satu di nust di Islamabad, Pakistan, yang lainnya di SLAC . Situs Bot adalah arsip dan analisis situs. Mereka saling melengkapi satu sama lain dengan menyediakan redundansi. Proyek XIWT memiliki situs arsip / monitor tersebut pada CNRI .
Situs arsip mengumpulkan informasi, dengan menggunakan HTTP, dari situs memantau secara berkala dan arsip itu. Mereka menyediakan data arsip ke situs analisis (s), yang pada gilirannya memberikan laporan yang tersedia melalui Web.
Arsitektur Pinger diilustrasikan di bawah ini:
gotchas
Beberapa perawatan yang diperlukan dalam pemilihan node untuk ping (lihat Persyaratan untuk Host WAN yang Dipantau ).Kami juga telah mengamati berbagai patologi dengan berbagai situs remote ketika menggunakan ping. Ini didokumentasikan dalam Pinger Pengukuran patologi .
Kalibrasi dan konteks di mana metrik round trip diukur didokumentasikan dalam pinger Kalibrasi dan Konteks , dan beberapa contoh bagaimana hasil ping terlihat ketika diambil dengan statistik yang tinggi, dan bagaimana mereka berhubungan dengan routing, dapat ditemukan dalam statistik hasil ping tinggi .
pengesahan
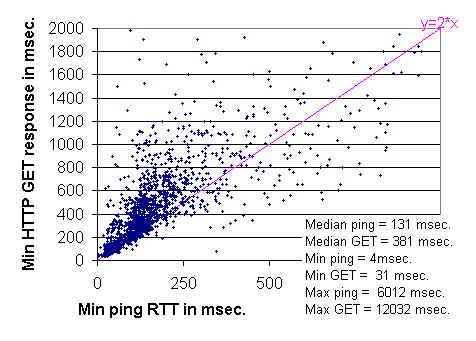
Kami telah divalidasi penggunaan ping dengan menunjukkan bahwa pengukuran yang dilakukan dengan itu berkorelasi dengan respon aplikasi. Korelasi antara batas bawah dari Web dan ping tanggapan terlihat pada gambar di bawah. Pengukuran dilakukan pada 18 Desember 1996, dari SLAC sekitar 1.760 situs yang diidentifikasi dalam cache NLANR . Untuk lebih jelasnya lihat Pengaruh Kinerja Internet di Web Times Respon , oleh Les Cottrell dan John Halperin, tidak diterbitkan, Januari 1997.Batas bawah sangat jelas terlihat di sekitar y = 2x tidak mengherankan karena: kemiringan 2 sesuai dengan HTTP mendapat yang mengambil dua kali waktu ping; waktu minimum ping adalah sekitar waktu round trip; dan transaksi TCP minimal melibatkan dua perjalanan putaran, satu round trip untuk bertukar kedua untuk mengirim permintaan dan menerima respon. Koneksi terminasi dilakukan asynchronous dan tidak muncul di waktu.
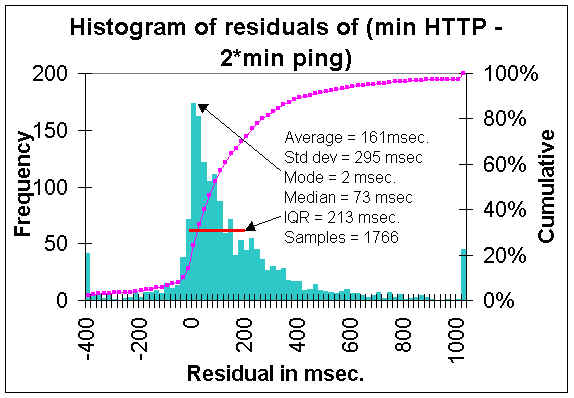
Batas bawah juga dapat divisualisasikan dengan menampilkan distribusi residual antara pengukuran dan garis y = 2 x (di mana y = HTTP GET waktu respon dan x waktu respon = Minimum ping). Distribusi seperti ditunjukkan di bawah ini. Curam di lipatan di frekuensi pengukuran sebagai salah satu mendekati nol nilai sisa ( y = 2x ) jelas. Inter Kuartil Range (IQR), kisaran residual antara di mana 25% dan 75% dari pengukuran jatuh, sekitar 220 msec, dan ditunjukkan pada plot oleh garis merah.
Cara alternatif untuk menunjukkan ping yang terkait dengan kinerja Web adalah untuk menunjukkan ping yang dapat digunakan untuk memprediksi dari satu set server Web direplikasi untuk mendapatkan halaman web dari. Untuk lebih lanjut tentang melihat ini Dynamic Server Selection di Internet , dengan Mark E. Crovella dan Robert L. Carter.
The Firehunter Studi Kasus Whitehouse Web Server menunjukkan bahwa meskipun ping respon tidak melacak kinerja Web yang abnormal baik, dalam hal ini kasus ping packet loss melakukan pekerjaan yang lebih baik.
Kualitas Internet penilaian layanan oleh Christian Huitema, menyediakan pengukuran dari berbagai komponen yang berkontribusi terhadap respon web. Komponen ini meliputi: RTT, kecepatan transmisi, DNS delay, koneksi delay, keterlambatan server, delay transmisi. Ini menunjukkan bahwa penundaan antara mengirim GET URL perintah dan penerimaan byte pertama dari respon adalah perkiraan server delay ( "di banyak server, meskipun belum tentu semua, penundaan ini sesuai dengan waktu yang diperlukan untuk menjadwalkan permintaan halaman , menyiapkan halaman dalam memori, dan mulai mengirim data ") dan mewakili antara 30 dan 40% dari durasi rata-rata transaksi. Untuk memudahkan itu, Anda mungkin perlu server yang lebih kuat. Mendapatkan koneksi lebih cepat jelas akan membantu yang lain 60% dari keterlambatan.
Juga lihat bagian bawah pada alat berbasis Non Ping untuk beberapa korelasi throughput dengan waktu round trip dan packet loss.
Apa yang kita Ukur
Kami menggunakan ping untuk mengukur waktu respon (waktu perjalanan di mili-detik (ms)), persentase packet loss, variabilitas waktu respon baik jangka pendek (waktu skala detik) dan lebih lama, dan kurangnya ketercapaian , yaitu tidak ada respon untuk suksesi ping. Untuk diskusi dan definisi reachability dan ketersediaan melihat Kinerja Internet: Analisis Data dan Visualisasi White Paper oleh XIWT . Kami juga mencatat informasi pada keluar dari paket ketertiban dan paket duplikat.Dengan data yang diukur kita mampu menciptakan baseline jangka panjang untuk harapan pada sarana / median dan variabilitas untuk waktu respon , throughput yang , dan packet loss . Dengan baseline ini di tempat kita dapat mengatur ekspektasi, memberikan informasi perencanaan, membuat ekstrapolasi dan mencari pengecualian (misalnya waktu respon saat ini lebih dari 3 standar deviasi lebih besar dari rata-rata selama 50 hari kerja terakhir) dan meningkatkan peringatan.
Kerugian
Kerugian adalah ukuran yang baik dari kualitas link (dalam hal tarif packet loss-nya) untuk banyak aplikasi berbasis TCP. Rugi biasanya disebabkan oleh kemacetan yang pada gilirannya menyebabkan antrian (misalnya dalam router) untuk mengisi dan paket yang akan dijatuhkan. Rugi juga bisa disebabkan oleh jaringan memberikan salinan sempurna dari paket. Hal ini biasanya disebabkan oleh kesalahan sedikit di link atau perangkat jaringan. Paxson (lihat End-lto-end Packet Dynamics ) dari pengukuran yang dilakukan pada tahun 1994 dan 1995 menyimpulkan bahwa sebagian besar kesalahan korupsi berasal dari link T1, dan tingkat khas adalah 1 di 5000 paket. Hal ini terkait dengan tingkat kesalahan bit untuk rata-rata 300byte paket sekitar 1 di 12 juta bit. IP memiliki checksum 16 bit, sehingga probabilitas tidak mendeteksi kesalahan dalam paket rusak adalah 1 65536, atau 1 di sekitar 300 juta paket. Sebuah studi yang lebih baru pada Ketika CRC dan TCP checksum tidak setuju diterbitkan pada bulan Agustus 2000, menunjukkan bahwa jejak paket internet selama dua tahun terakhir menunjukkan bahwa 1 dari 30.000 paket gagal TCP checksum, bahkan pada link di mana CRC link-tingkat harus menangkap semua tapi 1 di 4 miliar kesalahan. Kesalahan TCP checksum ini tingkat yang lebih tinggi (misalnya mereka dapat disebabkan oleh kesalahan bus di perangkat jaringan atau komputer, atau dengan TCP tumpukan kesalahan) daripada kesalahan tingkat link yang harus ditangkap oleh cek CRC.RTT
Waktu respon atau Round Trip Time (RTT) ketika diplot terhadap ukuran paket dapat memberikan gambaran tentang data rate ping (kilo Bytes / sec (KB / s)) ini menjadi semakin sulit sebagai salah satu pergi ke link kinerja tinggi, karena berbagai paket relatif kecil (biasanya <1500bytes), dan waktu resoltion terbatas. RTT berkaitan dengan jarak antara situs ditambah keterlambatan pada setiap hop di sepanjang jalan antara situs. Efek jarak secara kasar dapat ditandai dengan kecepatan cahaya serat, dan kira-kira diberikan oleh jarak / (0,6 * c) di mana c adalah kecepatan cahaya (ITU dalam dokumen G.144, meja A.1 merekomendasikan pengganda 0,005 msec / km, atau 0.66c). Menempatkan ini bersama-sama dengan penundaan hop, RTT R kira-kira diberikan oleh:R = 2 * (jarak / (0,6 * c) + hop * delay)
dimana faktor 2 adalah karena kita mengukur dan kali kembali untuk pulang-pergi. Hal ini digambarkan pada gambar di bawah, yang menunjukkan respon ping diukur sebagai fungsi jarak untuk antara 16 pasang situs yang terletak di Amerika Serikat, Eropa dan Jepang (Bologna-Florence, Jenewa-Lyon, Chicago-U dari Notre Dame, Tokyo -Osaka, Hamburg-Dresden, Bologna-Lyon, Jenewa-Mainz, Pittsburg-Cincinnatti, Jenewa-Copenhagen, Chicago-Austin, Jenewa-Lund, Chicago-San Francisco, Chicago-Hamburg, San Francisco-Tokyo, San Francisco-Geneva & Jenewa-Osaka). Segitiga biru adalah untuk RTT diukur (dalam milidetik), garis hitam adalah cocok untuk data, jalur hijau adalah untuk = x y (jarak) / (0.6 * c) , dan titik-titik merah lipat dalam penundaan hop dengan penundaan / hop dari sekitar 2.25ms untuk setiap arah (yaitu titik-titik merah adalah teoritis RTT fit). Kami menggunakan Berapa jauh? Halaman web untuk mendapatkan "seperti burung gagak lalat" jarak antara titik utama bersama setiap rute. Sebuah measuremet baru-baru ini lebih dibuat oleh Mark Spiller pada Maret 2001, sekitar 10 universitas dari UC Berkeley diukur penundaan router 500-700 usec dengan beberapa paku di 800-900 kisaran usec.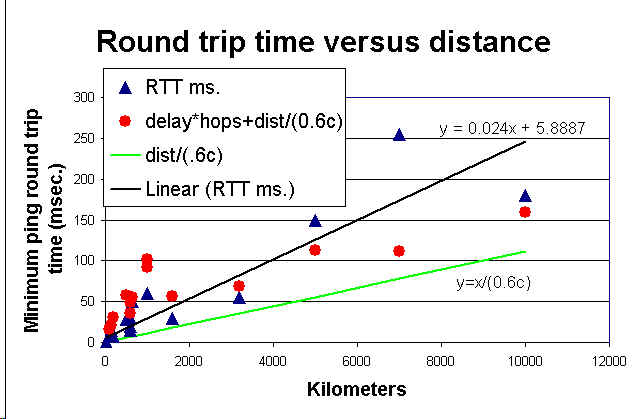
Panjang rute (R km ) dapat digunakan di tempat jarak untuk beberapa Delay (FTD) tujuan kinerja Bingkai Transfer. Jika D km adalah udara-rute jarak antara batas-batas, maka panjang rute dihitung sebagai berikut (ini adalah perhitungan yang sama seperti yang ditemukan di G.826 dokumen ITU).
- jika D km <1000 km, maka R km = 1,5 * D km
- jika 1000 km <= D km <= 1.200 km, maka R km = 1.500 km
- jika D km > 1200 km, maka R km = 1,25 * D km
Minimum memanjang ini RTT disebabkan oleh satelit geo-stasioner memberikan tanda tangan yang berguna untuk identitas Taht rute antara memantau dan sasaran termasuk satelit geo-staionary. Sebuah contoh dapat dilihat pada Gambar 5 dari2011-2012 Laporan ICFA-SCIC Pemantauan Kelompok Kerja .
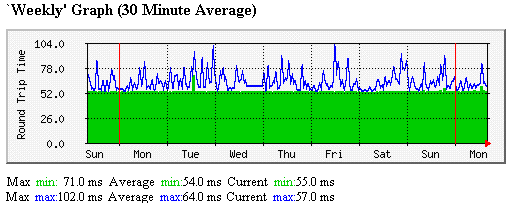
Penundaan pada setiap hop adalah fungsi dari 3 komponen utama: kecepatan router, interface tingkat clocking dan antrian di router. Dua mantan adalah konstan selama pendek (beberapa hari) periode waktu. Jadi RTT minimum memberikan ukuran dari jarak / (0,6 * c) + hop * ((kecepatan antarmuka / ukuran paket) + minimum router waktu forwarding) . Nomor ini harus menjadi fungsi linear dari ukuran paket. Efek router antrian, di sisi lain, tergantung pada proses acak antrian lebih dan lintas-lintas dan lebih bervariasi. Hal ini digambarkan dalam plot MRTG bawah yang menunjukkan minimum sangat stabil RTT (area hijau) dan RTT maksimum lebih acak (garis biru) diukur dari SLAC Universitas Wisconsin dari Minggu 25 Februari 2001, Senin 5 April 2001. sedikit blip di RTT sekitar tengah hari Selasa mungkin disebabkan oleh perubahan rute.
Non Ping Berdasarkan Alat
SLAC juga situs Surveyor. Surveyor maade salah satu cara delay pengukuran (tidak menggunakan ICMP), menggunakan perangkat Global Positioning System (GPS) untuk sinkronisasi waktu, dan berdedikasi monitoring / remote host. Kamimembandingkan data Pinger dan Surveyor untuk membandingkan dan kontras dua metode dan memverifikasi keabsahan ICMP echo. Salah satu perhatian dibesarkan dengan ICMP echo adalah kemungkinan Internet Service Provider (ISP) tingkat limititing ICMP dan sehingga menimbulkan pengukuran packet loss valid, untuk lebih lanjut tentang ini lihat bagian Gotchas di atas.Kami juga menggunakan alat-alat yang lebih kompleks seperti FTP (untuk mengukur kecepatan transfer massal) dan traceroute (untuk mengukur jalur dan jumlah hop). Namun, selain menjadi lebih sulit untuk mengatur dan mengotomatisasi, FTP lebih mengganggu pada jaringan dan lebih tergantung pada akhir simpul pemuatan. Jadi kita menggunakan FTP terutama dalam mode manual dan untuk mendapatkan ide dari seberapa baik pekerjaan tes ping (misalnya Korelasi antara FTP dan Ping dan Korelasi antara FTP throughput, Hops & Packet Loss ). Kami juga telah membandingkan Pinger prediksi throughput dengan pengukuran NetPerf . Cara lain untuk menghubungkan pengukuran throughput yang dengan packet loss adalah dengan Modeling TCP throughput .
Menghitung Skor Mean Opinion (MOS)
Industri telekomunikasi menggunakan Mean Opinion Score (MOS) sebagai metrik kualitas suara. Nilai-nilai MOS adalah: 1 = buruk; 2 = miskin; 3 = adil; 4 = baik; 5 = sangat baik. Berbagai khas untuk Voice over IP adalah 3,5-4,2 (lihatVoIPtroubleshooter.com ). Pada kenyataannya, bahkan koneksi yang sempurna dipengaruhi oleh algoritma kompresi codec, sehingga skor tertinggi yang paling codec dapat mencapai berada di 4,2-4,4 jangkauan. Untuk G.711 yang terbaik adalah 4.4 (atau Factor R (lihat ITU-T Recommendation G.107, "The E-Model, model komputasi untuk digunakan dalam perencanaan transmisi.") Dari 94,3) dan untuk G.729 yang melakukan kompresi yang signifikan itu adalah 4.1 (atau faktor R dari 84,3).Ada tiga faktor yang secara signifikan mempengaruhi kualitas panggilan: latency, packet loss, jitter. Faktor-faktor lain termasuk jenis codec, telepon (analog vs digital), PBX dll) Kami menunjukkan bagaimana kita menghitung jitter kemudian dalam tutorial ini. Kebanyakan solusi berbasis alat menghitung apa yang disebut "R" nilai dan kemudian menerapkan rumus untuk mengkonversi bahwa untuk skor MOS. Kami melakukan hal yang sama. R ini untuk perhitungan MOS relatif standar (lihat misalnya ITU - Sektor Telekomunikasi Standardisasi Temporary Dokumen XX-E WP 2/12 untuk metode baru). Skor nilai R adalah dari 0 sampai 100, di mana jumlah yang lebih tinggi lebih baik. Khas R untuk nilai MOS adalah: R = 90-100 => MOS = 4,3-5,0 (sangat puas), R = 80-90 => MOS = 4,0-4,3 (puas), R = 70-80 => MOS = 3,6 -4,0 (beberapa disatisfaction), R = 60-70 => MOS = 3,1-3,6 (lebih disatisfaction), R = 50-60 => MOS = 2,6-3,1 (Paling disatisfaction), R = 0-50 => MOS = 1,0-2,6 (tidak disarankan). Untuk mengkonversi latency, kerugian, jitter untuk MOS kita mengikuti metode Nessoft ini . Mereka menggunakan (dalam pseudo code):
#Take Rata-rata round trip latency (dalam milidetik), menambahkan #round perjalanan jitter, tapi ganda dampak untuk latency #then menambahkan 10 untuk latency protokol (dalam milidetik). EffectiveLatency = (AverageLatency + Jitter * 2 + 10) #Implement kurva dasar - mengurangi 4 untuk nilai R di 160ms latency # (round trip). Apa pun lebih yang mendapat jauh lebih agresif pemotongan. jika EffectiveLatency <160 maka R = 93,2 - (EffectiveLatency / 40) lain R = 93,2 - (EffectiveLatency - 120) / 10 #Now, mari kita mengurangi 2,5 nilai R per persentase packet loss (yaitu #loss dari 5% akan dimasukkan sebagai 5). R = R - (packetloss * 2,5) . #Convert R menjadi nilai MOS (ini adalah formula dikenal) jika R <0 maka MOS = 1 lagi MOS = 1 + (0,035) * R + (0,000007) * R * (R-60) * (100-R)Juga lihat berikut untuk beberapa alat pengukuran dan / atau penjelasan:
Menghitung Jaringan Kontribusi untuk Transaksi Kali
ITU telah datang dengan metode untuk menghitung kontribusi jaringan ke waktu transaksi di ITU-T Rec.G1040 "kontribusi Jaringan ke waktu transaksi" . Kontribusi tergantung pada RTT , kehilangan probabilitas ( p ), yang Retransmisi Time Out ( RTO ) dan jumlah putaran perjalanan yang terlibat ( n ) dalam transaksi. Jaringan Kontribusi untuk Transation Waktu ( NCTT ) diberikan sebagai:Rata-rata (NCTT) = (n * RTT) + (p * n * RTO)
Nilai-nilai khas untuk n 8, untuk RTO kita mengambil 2,5 detik, kita mengambil RTT dan kehilangan probabilitas ( p ) dari pengukuran Pinger.
Berasal TCP throughput yang dari pengukuran ping
Perilaku makroskopik algoritma TCP menghindari kemacetan oleh Mathis, Semke, Mahdavi & Ott dalam Komunikasi Komputer Review, 27 (3), Juli 1997 memberikan formula singkat dan berguna untuk batas atas transfer rate:Tingkat <(MSS / RTT) * (1 / sqrt (p))
di mana:Tingkat : adalah TCP transfer rate
MSS : adalah ukuran segmen maksimum (tetap untuk setiap jalur Internet, biasanya 1460 bytes)
RTT : adalah waktu round trip (yang diukur dengan TCP)
p : adalah tingkat packet loss.
Sebenarnya kerugian yang kerugian TCP yang belum tentu identik dengan kerugian ping (misalnya standar TCP memprovokasi kerugian sebagai bagian dari estimasi kemacetan nya). Juga RTT ping berbeda dari cara TCP memperkirakan RTT (lihat misalnya Meningkatkan Pulang-Trip Time Perkiraan di Reliable Transport Protocol .) Namun, terutama untuk kinerja yang lebih rendah sponsor itu adalah estimator yang wajar.
Bentuk peningkatan persamaan di atas dapat ditemukan di: Modeling TCP throughput yang: Sebuah model sederhana dan validasi empiris oleh J. Padhye, V. Firoiu, D. Townsley dan J. Kurose, di Proc. SIGCOMM Symp. Komunikasi Arsitektur dan Protokol 1998 Agustus, pp. 304-314.
Rate = min (W max / RTT, 1 / ((RTT / sqrt (2 * b * p / 3) + min (1, 3 * sqrt (3 * b * p / 8)) * (1 + 32 * p * p))))
dimana:W max : adalah ukuran kemacetan window maksimal.
b : adalah jumlah paket diakui oleh ACK tertunda. Banyak implementasi penerima TCP mengirim satu ACK kumulatif selama dua paket berturut-turut menerima (lihat W. Stevens. TCP / IP Illustrated, Vol. 1 Protokol. Addison-Wesley, 1994), sehingga b biasanya 2.
Perilaku throughput sebagai fungsi dari kerugian dan RTT dapat dilihat dengan melihat throughput dibandingkan RTT dan kehilangan . Kami telah menggunakan rumus Mathis untuk membandingkan pinger dan NetPerf pengukuran throughput.
Normalisasi throughput Berasal
Untuk mengurangi efek dari 1 / RTT dalam rumus Mathis untuk throughput berasal, kita menormalkan throughput dengan menggunakannorm_throughput = throughput yang * min_RTT (wilayah terpencil) / min_rtt (monitoring_region)
Kelangsungan koneksi
Ini adalah metrik untuk mengidentifikasi keterusterangan dari koneksi berween 2 node di lokasi yang dikenal. Nilai Keterusterangan dekat dengan salah satu berarti jalur antara host mengikuti rute lingkaran kira-kira besar. Nilai jauh lebih kecil dari 1 berarti jalan sangat tidak langsung. Derivasi dari keterusterangan koefisien Directivity berdasarkan minimu RTT diberikan di sini .RTD = Round Trip Jarak,
RTD [km] = Directivity * min_RTT [msec] * 200 [km / msec ]
Directivity memungkinkan untuk keterlambatan dalam peralatan jaringan dan indirectness dari rute yang sebenarnya.
D = 1 cara jarak
Directivity = D (km) / (min_RTT [msec] * 100 [km / msec])
- Max ( Directivity ) = 1 = langsung (lingkaran besar) rute dan tidak ada penundaan jaringan
- Directivity diperoleh dari mini mum RTT biasanya ~ 0.45
- nilai-nilai yang rendah biasanya berarti rute yang sangat tidak langsung, atau satelit atau koneksi yang lambat (misalnya nirkabel)
- Directivity > 1 mungkin mengidentifikasi koordinat buruk bagi tuan rumah.
Akses ke data
Ping data mentah dapat diakses publik, melihat Mengakses data Pinger untuk bagaimana untuk mendapatkan data dan format. Data yang dirangkum juga tersedia dari web di Excel tab-dipisahkan-nilai (.tsv) format dari laporan rinci Pinger .Ping dari Nodes Kolaborator '
Analisis Data & Presentasi
Plot harian
Ping kali respon diplot untuk setiap setengah jam untuk setiap node, misalnya melihat alur Smokeping jika RTT dan kehilangan . Ini terutama digunakan untuk trouble shooting (misalnya melihat apakah itu mendapat dramatis buruk dalam beberapa jam terakhir).
Plot 3D dari Node vs Response vs Time of Day
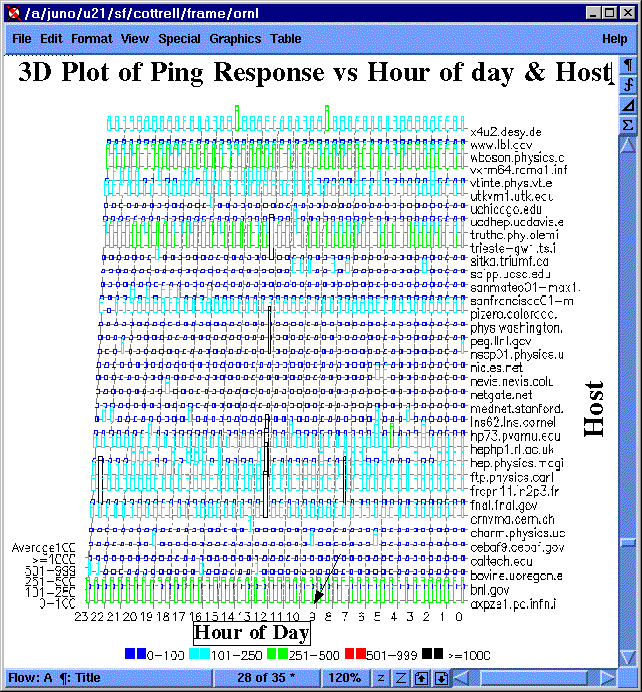 |
Dengan merencanakan plot 3D node terhadap waktu dibandingkan respon kita dapat mencari korelasi dari beberapa node memiliki kinerja yang buruk atau menjadi tidak terjangkau pada waktu yang sama (mungkin karena penyebab umum), atau node yang diberikan memiliki respon yang buruk atau menjadi tidak terjangkau untuk waktu yang panjang. Di sebelah kiri adalah contoh yang menunjukkan beberapa host (hitam) semua menjadi tidak terjangkau sekitar jam 12 siang. |
Terakhir 180 Hari plot:
Grafik jangka panjang menunjukkan waktu respon, packet loss dan unreachability untuk 180 hari terakhir juga dapat menunjukkan apakah layanan semakin buruk (atau lebih baik ).
Bulanan Ping Response & Loss Averages akan kembali selama bertahun-tahun:
| Tabel median bulanan dari prime time (7 am- 19:00 pada hari kerja) waktu respon 1.000 byte ping dan 100 byte ping packet loss memungkinkan kita untuk melihat data akan kembali untuk waktu yang lebih lama. Tabel data ini dapat diekspor ke Excel dan grafik yang terbuat dari kinerja ping packet loss jangka panjang. |  |
Diam Jaringan Frekuensi
Ketika kita mendapatkan kerugian sampel nol paket (sampel mengacu pada satu set n ping), kita merujuk ke jaringan sebagai diam (atau non-sibuk). Kami kemudian dapat mengukur frekuensi persentase seberapa sering jaringan ditemukan menjadi diam. Persentase yang tinggi merupakan indikasi yang baik (diam atau non-berat dimuat) jaringan. Misalnya jaringan yang sibuk 8 jam kerja per minggu hari, dan diam pada waktu lain akan memiliki persentase diam sekitar 75% ~ (total_hours / minggu - 5 hari kerja / minggu * 8 jam / hari) / (total_hours / minggu) . Cara ini mewakili hilangnya teh mirip maksud untuk metrik telepon bebas dari kesalahan detik.
The Diam Jaringan Frekuensi tabel menunjukkan persentase (frekuensi) dari sampel (di mana sampel adalah seperangkat 10 100 ping byte) yang diukur nol packet loss. Sampel termasuk dalam setiap persentase melaporkan semua sampel untuk setiap situs untuk setiap bulan (yaitu dari urutan 30 hari * 48 (30 menit periode) atau sekitar 1.440 sampel) per situs / bulan.
Jitter , lihat juga jitter ,
Variabilitas jangka pendek atau "jitter" dari waktu respon sangat penting untuk aplikasi real-time seperti telepon. Web browsing dan email cukup tahan terhadap jitter, tetapi setiap jenis media streaming (voice, video, musik) cukup suceptible untuk jitter. Jitter adalah gejala bahwa ada kemacetan, atau tidak cukup bandwidt untuk menangani lalu lintas. Jitter menentukan panjang VoIP codec de-jitter penyangga untuk mencegah over atau under-aliran. Tujuan bisa menentukan yang mengatakan 95% dari delay variasi harus berada dalam interval [-30msec, + 30msec].
Salah satu metode memerlukan suntik paket secara berkala ke jaringan dan mengukur variabilitas dalam waktu kedatangan. IETF memiliki IP Packet Keterlambatan Variasi Metric untuk IP Metrik Kinerja (IPPM) (lihat juga RTP: A Transport Protocol untuk Aplikasi Real-Time , RFC 2679 dan RFC 5481
Kami mengukur variabilitas sesaat atau "jitter" dalam dua cara.
- Biarkan pengukuran-i dari waktu round trip (RTT) menjadi R i , maka kita mengambil "jitter" sebagai Inter Kuartil Range (IQR) dari distribusi frekuensi R . Lihat SLAC <=> CERN round trip delay untuk contoh distribusi tersebut.
- Dalam metode kedua kami memperluas draft IETF pada Sesaat Packet Penundaan Variasi Metric untuk IPPM , yang merupakan satu arah metrik, untuk dua arah ping. Kami mengambil IQR dari distribusi frekuensi dR , di mana dR i = R i r i-1 . Perhatikan bahwa ketika menghitung dR paket tidak harus berdekatan. Lihat SLAC <=> CERN dua arah paket seketika variasi delay untuk contoh distribusi tersebut.
Kedua distribusi di atas dapat dilihat untuk menjadi non-Gaussian itulah sebabnya kami menggunakan IQR bukan standar deviasi sebagai ukuran "jitter". Juga lihat RFC 1889/3550.
Dengan melihat Ping "jitter" antara SLAC dan CERN, DESY & FNAL dapat dilihat bahwa kedua metode perhitungan jitter track satu sama lain (IQR metode pertama diberi label dan yang kedua diberi label IPD pada gambar) dengan baik. Mereka bervariasi oleh dua perintah magntitude sepanjang hari. Jitter antara SLAC & FNAL jauh lebih rendah dibandingkan antara SLAC dan DESY atau CERN. Hal ini juga dicatat bahwa CERN memiliki jitter lebih besar pada siang hari Eropa, sementara DESY memiliki jitter lebih besar pada siang hari AS.
Kami juga telah memperoleh ukuran jitter dengan mengambil nilai absolut dR , yaitu | dR | . Hal ini kadang-kadang disebut sebagai "metode moving range" (lihat Desain statistik dan Analisis Eksperimen , Robert L. Mason, Richard F. Tamu dan James L. Hess. John Wiley & Sons, 1989). Hal ini juga digunakan dalam RFC 2598 sebagai definisi jitter ( RFC 1889 memiliki definisi lain dari jitter untuk digunakan real time dan perhitungan) Lihat Histogram dari kisaran bergerak untuk contoh. Dalam gambar ini, garis magenta adalah total kumulatif, garis biru adalah fit exponentail untuk data, dan jalur hijau adalah cocok seri kekuatan untuk data. Perhatikan bahwa semua 3 dari grafik di bagian ini pada jitter adalah representasi dari data yang identik.
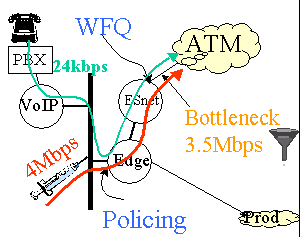 Dalam rangka untuk lebih dekat memahami persyaratan untuk VoIP dan khususnya dampak dari penerapan Quality of Service (QoS) tindakan, kami telah menetapkan suatu testbed VoIP antara SLAC dan LBNL. Sebuah skema kasar ditunjukkan ke kanan. Hanya setengah sirkuit SLAC ditunjukkan dalam skema, akhir LBNL mirip. Seorang pengguna dapat mengangkat telepon yang terhubung ke PBX pada akhir SLAC dan memanggil pengguna lain di telepon di LBNL melalui VoIP Cisco router gateway. gateway mengkodekan, kompres dll aliran suara ke dalam paket IP (menggunakan standar G.729) menciptakan sekitar 24kbps lalu lintas. Aliran VoIP mencakup TCP (untuk signaling) dan UDP. Sambungan dari router ESNet ke ATM awan adalah 3,5 Mbps ATM sirkuit virtual permanen (PVC). Dengan tidak ada lalu lintas bersaing pada link, panggilan tersambung dan percakapan berlanjut secara normal dengan kualitas yang baik. Kemudian kita menyuntikkan 4 Mbps lalu lintas ke berbagi 10 Mbps Ethernet bahwa router VoIP terhubung ke. Pada tahap ini, koneksi VoIP rusak dan ada koneksi lebih lanjut dapat dibuat. Kami kemudian menggunakan fitur Edge router Committed Access Rate (CAR) untuk label paket VoIP 'dengan menetapkan Per Hop Perilaku (PHB) bit. The ESNet router kemudian diatur untuk menggunakan fitur Weighted Adil Queuing (WFQ) untuk mempercepat paket VoIP. Dalam konfigurasi ini koneksi suara dapat lagi dibuat dan percakapan lagi berkualitas baik.
Dalam rangka untuk lebih dekat memahami persyaratan untuk VoIP dan khususnya dampak dari penerapan Quality of Service (QoS) tindakan, kami telah menetapkan suatu testbed VoIP antara SLAC dan LBNL. Sebuah skema kasar ditunjukkan ke kanan. Hanya setengah sirkuit SLAC ditunjukkan dalam skema, akhir LBNL mirip. Seorang pengguna dapat mengangkat telepon yang terhubung ke PBX pada akhir SLAC dan memanggil pengguna lain di telepon di LBNL melalui VoIP Cisco router gateway. gateway mengkodekan, kompres dll aliran suara ke dalam paket IP (menggunakan standar G.729) menciptakan sekitar 24kbps lalu lintas. Aliran VoIP mencakup TCP (untuk signaling) dan UDP. Sambungan dari router ESNet ke ATM awan adalah 3,5 Mbps ATM sirkuit virtual permanen (PVC). Dengan tidak ada lalu lintas bersaing pada link, panggilan tersambung dan percakapan berlanjut secara normal dengan kualitas yang baik. Kemudian kita menyuntikkan 4 Mbps lalu lintas ke berbagi 10 Mbps Ethernet bahwa router VoIP terhubung ke. Pada tahap ini, koneksi VoIP rusak dan ada koneksi lebih lanjut dapat dibuat. Kami kemudian menggunakan fitur Edge router Committed Access Rate (CAR) untuk label paket VoIP 'dengan menetapkan Per Hop Perilaku (PHB) bit. The ESNet router kemudian diatur untuk menggunakan fitur Weighted Adil Queuing (WFQ) untuk mempercepat paket VoIP. Dalam konfigurasi ini koneksi suara dapat lagi dibuat dan percakapan lagi berkualitas baik.
layanan Prediktabilitas
Sebuah ukuran variabilitas layanan (atau ping prediktabilitas ) dapat diperoleh dengan cara plot pencar dari variabel berdimensi rata-rata harian ping data rate / maksimum ping data rate dibandingkan rata-rata harian ping sukses / maksimum keberhasilan ping (di mana% keberhasilan = ( total paket - paket yang hilang) / Jumlah paket) . Berikut ping data ratedidefinisikan sebagai (2 * byte dalam paket ping) / waktu respon . 2 adalah karena paket harus pergi keluar dan kembali. Cara lain untuk melihat pada rasio adalah bahwa angka mendekati 1 menunjukkan bahwa rata-rata kinerja dekat dengan kinerja terbaik. Nomor tidak dekat dengan 1 biasanya disebabkan oleh variasi yang besar dalam waktu ping antara jam kerja dan jam non-kerja, lihat misalnya ping respon UCD untuk 3 Oktober 1996 untuk contoh variasi diurnal. Beberapa contoh ping prediktabilitas plot pencar untuk berbagai bagian dari internet yang diukur dari SLAC untuk Juli 1995 dan Maret 1996 dapat dilihat di bawah ini.
| Tanggal | semua Host | ESNet | N. America | Internasional |
|---|---|---|---|---|
| '95 Juli | 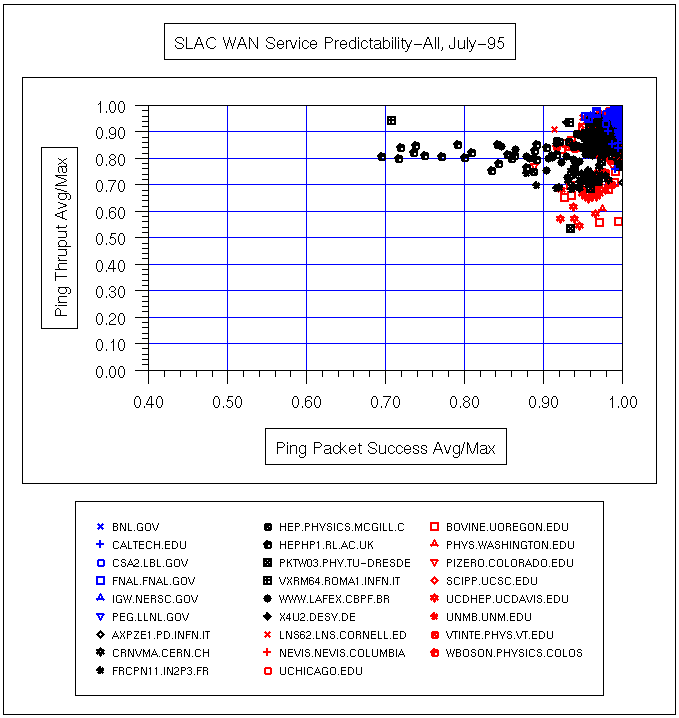 |
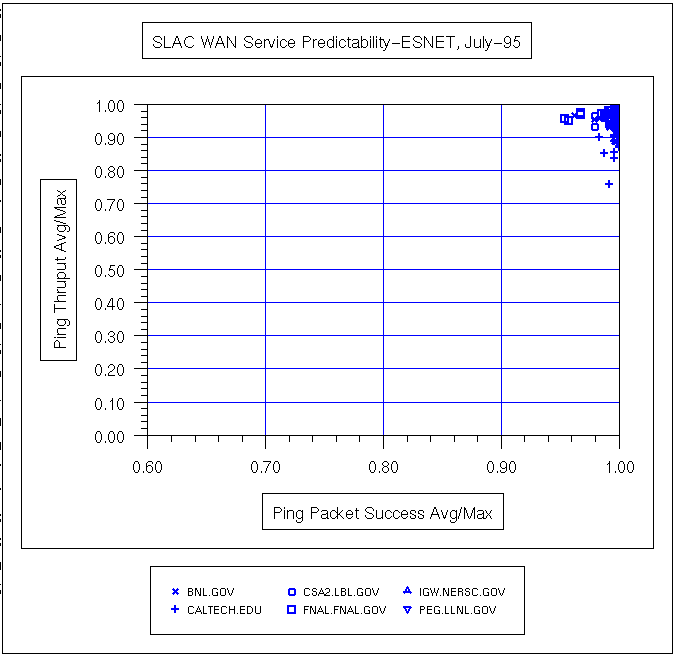 |
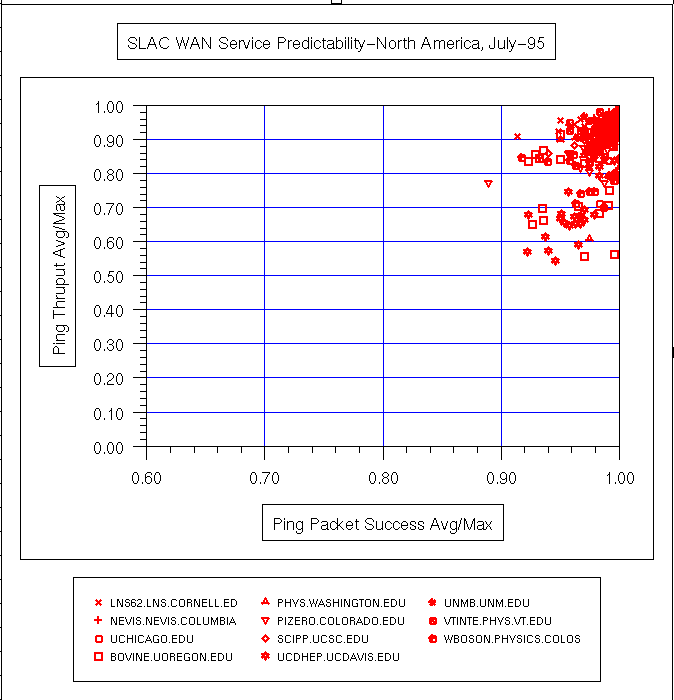 |
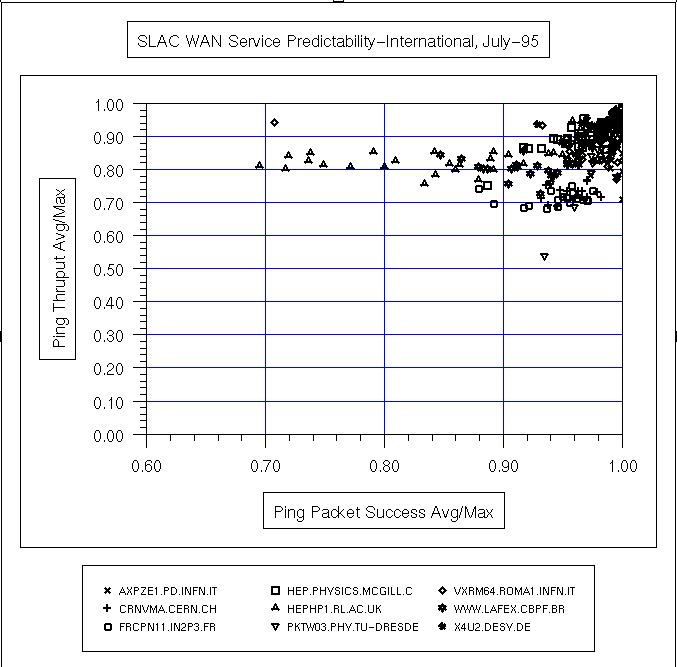 |
| Mar '96 | 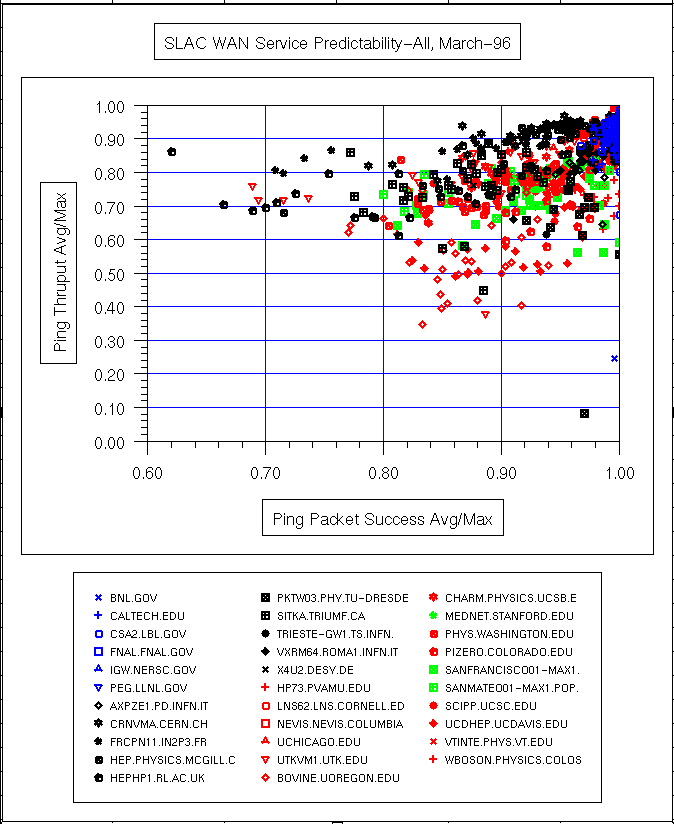 |
 |
 |
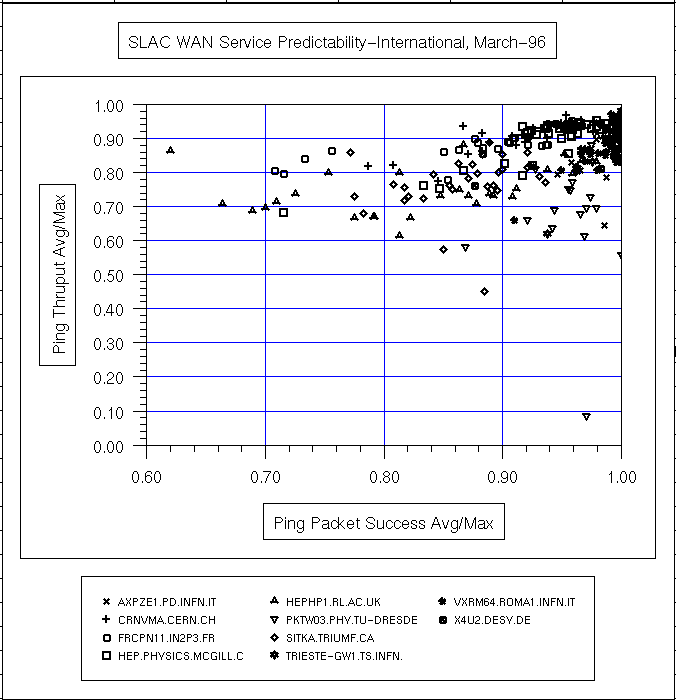 |
Satu dapat mengurangi informasi sebar ini lebih lanjut dengan memplot keberhasilan ping paket / maksimum keberhasilan ping paket rata-rata bulanan versus rata ping thruput / ping thruput maksimum bulanan untuk bulan yang berbeda untuk melihat perubahan. Seperti plot untuk beberapa N. node Amerika untuk bulan Juli 1995 dan Maret 1996 menunjukkan perubahan besar, dalam semua kasus yang lebih buruk (poin lebih baru yang lebih ke kiri bawah plot).
ketidakpastian
Satu juga dapat menghitung jarak dari setiap titik prediktabilitas dari koordinat (1,1). Kami menormalkan ke nilai maksimum 1 dengan membagi jarak dengan sqrt (2). Saya lihat ini sebagai ping ketidakpastian , karena memberikan persentase indikator ketidakpastian kinerja ping.
reachability
Dengan melihat ping data untuk mengidentifikasi 30 periode menit bila tidak ada tanggapan ping diterima dari host yang diberikan, seseorang dapat mengidentifikasi ketika tuan rumah turun. Menggunakan informasi ini satu dapat menghitung ping unreachability = (# periode dengan Node bawah / total jumlah periode) , # Bawah periode, Mean Time Antara Kegagalan (MTBF atau Mean Time To Failue MTTF)) dan Mean Time To Repair (MTTR). Perhatikan bahwa MTBF = sample_time / ping_unreachability mana untuk waktu sampel Pinger adalah 30 menit. Reachability sangat bergantung pada remote host, misalnya jika remote host dinamai atau dihapus, tuan rumah akan tampil terjangkau namun mungkin ada yang salah dengan jaringan. Jadi sebelum menggunakan data ini untuk menyediakan tren jaringan jangka panjang data harus hati-hati digosok untuk efek non-jaringan. Contoh ping reachability dan Bawah laporan yang tersedia.
Satu juga dapat mengukur frekuensi pemadaman panjang menggunakan probe aktif dan mencatat durasi waktu yang probe sekuensial tidak mendapatkan melalui.
Ano / ther metrik yang kadang-kadang digunakan untuk menunjukkan ketersediaan sirkuit telepon Kesalahan-bebas detik . Beberapa pengukuran tentang hal ini dapat ditemukan di Kesalahan detik bebas antara SLAC, FNAL, CMU dan CERN .
Ada juga RFC IETF pada Mengukur Konektivitas dan dokumen tentang A Taksonomi Modern High Availability yang mungkin berguna.
Keluar dari paket Orde
Pinger menggunakan algoritma yang sangat sederhana untuk mengidentifikasi dan melaporkan keluar dari paket pesanan. Untuk masing-masing sampel dari 10 paket, yang terlihat untuk melihat apakah nomor urutan tanggapan yang diterima dalam urutan yang sama seperti permintaan dikirim. Jika tidak dari sampel yang ditandai sebagai memiliki satu atau lebih dari tanggapan order. Untuk interval tertentu (misalnya satu bulan) nilai dilaporkan untuk ou order adalah sebagian kecil dari sampel yang ditandai dengan keluar dari tanggapan urutan ping. Karena paket ping dikirim pada satu interval kedua diharapkan fraksi dari sampel order akan sangat kecil, dan mungkin perlu dilakukan setiap kali itu tidak.
duplikat Paket
tanggapan ping duplikat dapat disebabkan oleh:
- Lebih dari satu host memiliki alamat IP yang sama, sehingga semua host ini akan menanggapi permintaan ICMP echo.
- Alamat IP ping mungkin alamat broadcast.
- Tuan rumah memiliki beberapa tumpukan TCP terikat ke adaptor Ethernet (lihat http://www.doxpara.com/read.php/tcp_chorusing.html).
- Sebuah router percaya itu memiliki dua rute dengan yang dapat mencapai host akhir dan (mungkin keliru) meneruskan ICMP permintaan oleh kedua rute, sehingga tuan rumah akhirnya melihat dua permintaan gema dan merespon dua kali.
- Ada mungkin dua atau lebih (non-routed) jalur ke host akhir dan setiap permintaan diteruskan oleh lebih dari satu jalur.
- Sebuah kotak NAT nakal.
Beberapa tes yang dapat membantu meliputi:
- Ping router sepanjang rute untuk melihat apakah mereka merespon dengan duplikat.
- Menangkap paket-paket ping dan melihat apakah semua paket yang kembali dari alamat Ethernet yang sama.
Ide dari prvalence paket ping duplikat berasal dari pengukuran Pinger 31 Maret 2012-703 host di lebih dari 600 negara. Host ini 15 menanggapi dengan duplikat ping. Untuk 13 dari 15 host itu terjadi pada kedua 100 dan 1000 ping Byte. Dari 10 ping mengirim 6 host telah 1 ping digandakan, 5 telah 2 ping digandakan, 2 memiliki 4 ping digandakan, 1 memiliki 3 ping digandakan dan 1 kembali 12 ping untuk setiap ping dikirim. Situs host berkisar dari laboratorium nasional (CERN, IHEP SU), negara-negara maju (Israel), negara-negara berkembang (Burkina Faso, Malawi, Mauritius, Sierra Leone, Swaziland, Zambia), dan situs pendidikan (SDSC). Pinger hanya melaporkan keduanya, ada duplikasi atau tidak. Sebuah metrik berguna adalah untuk melaporkan jumlah ping diterima / nomor ping dikirim . Jumlah yang diterima mungkin tergantung pada pilihan perintah ping. Salah satu pilihan akan mengirim sejumlah tertentu ping sampai menerima bahwa banyak kembali atau kali keluar. Pilihan lain akan mengirim 10 ping dan menunggu (atau waktu) sampai mereka diterima. Jadi nilai metrik mungkin juga tergantung pada perintah ping.
Kombinasi dari semua tindakan ping
Satu dapat mengumpulkan plot semua langkah di atas ping (loss, respon, unreachability dan ketidakpastian) untuk mencoba dan menunjukkan kombinasi pengukuran untuk satu set host untuk jangka waktu tertentu. Plot bawah untuk 01-11 Maret 1997, kelompok host ke dalam kelompok logis (ESNet, N. America West, ...) dan dalam kelompok peringkat host oleh% 100 byte ping packet loss untuk SLAC prime time (07:00 - 07:00 hari kerja), juga ditunjukkan oleh garis biru adalah prime time waktu ping respon, dan negatif dari ping% unreachability dan ketidakpastian. 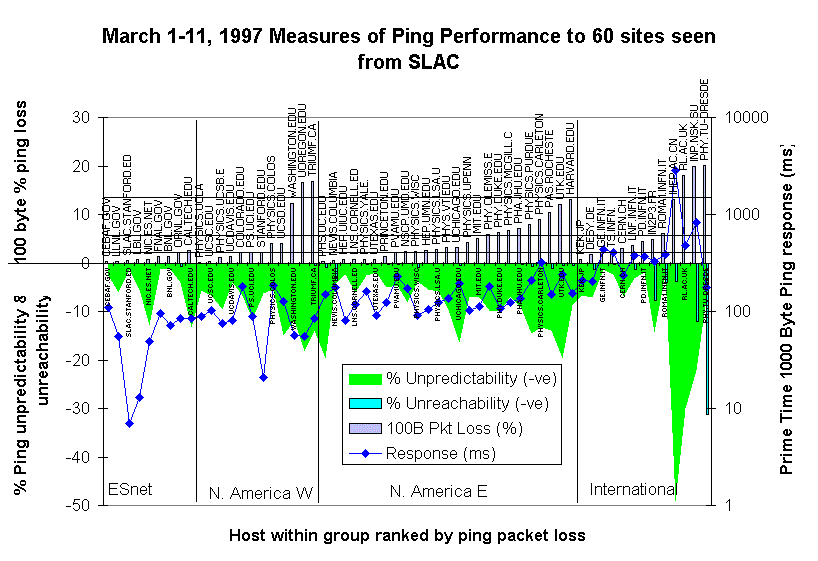
Di plot di atas, kerugian dan waktu respon yang diukur selama SLAC prime time (07:00-07:00, hari kerja), langkah-langkah lain untuk sepanjang waktu.
- Tingkat kerugian diplot sebagai grafik batang di atas y = 0 axis dan untuk 100 byte payload paket ping. garis horizontal ditunjukkan pada kerugian paket 1%, 5% dan 12% pada batas kualitas koneksi yang didefinisikan di atas.
- Waktu respon diplot sebagai garis biru pada sumbu log, berlabel ke kanan, dan waktu round trip untuk 1000 byte paket ping payload.
- The unreachability tuan diplot sebagai grafik batang negatif yang memanjang dari y = 0 sumbu. Sebuah host dianggap unreachable pada interval 30 menit jika tidak menanggapi salah satu 21 ping dilakukan pada interval 30 menit.
- Ketidakpastian host diplot dalam hijau di sini sebagai nilai negatif, dapat berkisar dari 0 (benar-benar tak terduga) untuk 1 (sangat diprediksi) dan merupakan ukuran dari variabilitas waktu ping respon dan kehilangan selama setiap hari 24 jam. Hal ini didefinisikan secara lebih rinci dalam Ping Ketidakpastian .
Pengamatan berikut juga relevan:
- host ESNet pada umumnya memiliki packet loss yang baik (median 0,79%). Kerugian paket rata-rata untuk kelompok lain bervariasi dari sekitar 4,5% (N. Amerika Timur) menjadi 7,7% (International). Biasanya 25% -35% dari tuan rumah di kelompok non-ESNet berada di miskin untuk kisaran buruk.
- Waktu respon untuk ESNet tuan rumah rata-rata di sekitar 50ms, untuk N. America Wes itu adalah sekitar 80ms, untuk Amerika Utara Timur sekitar 150ms dan untuk host International sekitar 200ms.
- Sebagian besar masalah terjangkau yang terbatas pada beberapa host terutama pada kelompok International (Dresden, Novosibirsk, Florence).
- ketidakpastian yang paling ditandai selama beberapa host Internasional dan kira-kira melacak packet loss.
Kualitas
Agar dapat meringkas data sehingga signifikansi dapat dengan cepat memahami, kami telah mencoba untuk mengkarakterisasi kualitas kinerja link. Beberapa laporan yang menarik di bawah ini:
- ESNet melaporkan kebutuhan bandwidth.
- QoS Persyaratan Aplikasi Jaringan di Internet .
- Jaringan QoS Kebutuhan Advanced Aplikasi Internet: A Survey
Berikut adalah beberapa langkah-langkah lain yang diselenggarakan oleh metrik.
Menunda
Komoditas scarcest dan paling berharga adalah waktu. Studi di tahun 1970-an dan awal 1980-an oleh Walt Doherty dari IBM dan lain-lain menunjukkan nilai ekonomi Rapid Response Time:
| 0-0.4s | produktivitas yang tinggi respon interaktif |
| 0.4-2s | Rezim sepenuhnya interaktif |
| 2-12s | Rezim sporadis interaktif |
| 12s-600s | Istirahat di rezim kontak |
| 600s | rezim Batch |
Untuk lebih lanjut tentang dampak waktu respon melihat The Psychology of Interaksi Manusia Komputer , Stuart K. Card, Thomas P. Moran dan Allen Newell, ISBN 0-89859-243-7, diterbitkan oleh Lawrence Erlbaum Associates (1983).
Ada ambang batas sekitar 4-5s mana keluhan meningkat dengan cepat. Untuk beberapa aplikasi Internet yang lebih baru ada ambang batas lainnya, misalnya untuk suara ambang batas untuk satu arah delay muncul pada sekitar 150ms (lihat ITU Rekomendasi G.114 waktu transmisi satu arah , Feb 1996) - di bawah satu ini dapat memiliki panggilan kualitas tol, dan di atas titik itu, penundaan menyebabkan kesulitan bagi orang yang mencoba untuk memiliki percakapan dan frustrasi tumbuh.
Untuk menjaga waktu dalam musik, peneliti Stanford menemukan bahwa jumlah optimum latency 11 milidetik. Di bawah ini yang delay dan orang-orang cenderung untuk mempercepat. Atas keterlambatan itu dan mereka cenderung untuk memperlambat. Setelah sekitar 50 milidetik (atau 70), pertunjukan cenderung untuk benar-benar berantakan.
Telinga manusia mempersepsikan suara yang simultan hanya jika mereka mendengar dalam waktu 20 ms satu sama lain, lihat http://www.mercurynews.com/News/ci_27039996/Music-at-the-speed-of-light-is-researchers- tujuan
Untuk real-time multimedia (H.323) Pengukuran Kinerja dan Analisis H.323 Lalu Lintas memberikan salah satu cara delay (kira-kira faktor dua untuk mendapatkan RTT), dari: 0-150ms = Baik, 150-300ms = accceptable, dan> 300ms = miskin.
The SLA untuk satu arah sasaran jaringan latency untuk Cisco TelePresence di bawah 150 msec. Ini tidak termasuk latency yang disebabkan oleh encoding dan decoding pada titik akhir CTS.
Semua paket yang terdiri dari frame video harus disampaikan ke titik TelePresence akhir sebelum buffer ulangan habis. Jika tidak degradasi kualitas video dapat terjadi. The puncak ke puncak sasaran jitter untuk Cisco TelePresence adalah di bawah 10 msec.
Kertas di Internet pada Kecepatan Cahaya memberikan beberapa contoh tentang pentingnya mengurangi RTT. Contohnya termasuk mesin pencari seperti Google dan Bing, penjualan Amazon dan bursa
Untuk kontrol haptic real time dan umpan balik untuk operasi medis, peneliti Stanford (lihat Shah, A., Harris, D., & Gutierrez, D. (2002). "Kinerja Remote Anatomi dan Aplikasi Pelatihan Bedah bawah Bervariasi Kondisi Jaringan." Dunia konferensi Pendidikan Multimedia, Hypermedia dan Telekomunikasi 2002 (1), 662-667 ) menemukan bahwa salah satu cara penundaan <= 80msec. diperlukan.
The Peta Internet Weather mengidentifikasi seburuk apapun hubungan dengan penundaan selama 300ms.
Kerugian
Untuk karakterisasi kualitas kami telah difokuskan terutama pada kerugian paket. Pengamatan kami telah bahwa di atas 4-6% packet loss video conferencing menjadi menjengkelkan, dan speaker non bahasa ibu menjadi tidak dapat berkomunikasi. Terjadinya penundaan panjang 4 detik atau lebih pada frekuensi 4-5% atau lebih juga menjengkelkan untuk kegiatan interaktif seperti telnet dan X jendela. Di atas 10-12% packet loss ada tingkat yang tidak dapat diterima kembali ke belakang hilangnya paket dan timeout sangat panjang, koneksi mulai mendapatkan rusak, dan konferensi video tidak dapat digunakan (lihat juga Isu transmisi paket berguna untuk multimedia melalui internet , di mana mereka mengatakan pada halaman 10 "kami menyimpulkan bahwa untuk streaming video ini, kualitas video tidak dapat dimengerti ketika tarif packet loss melebihi 12%" . di MSF sisi lain kata (multi Service Forum) pejabat sebagai akibat dari tes pada berikutnya- jaringan generasi untuk IPTV "pengujian menunjukkan bahwa bahkan satu setengah dari 1% dari kehilangan paket dalam aliran video dapat membuat kualitas video tidak dapat diterima untuk pengguna akhir" (lihat Computerworld, 29 Oktober 2008 ).
Awalnya tingkat kualitas untuk packet loss yang ditetapkan sebesar 0-1% = baik, 1-5% = diterima, 5-12% = miskin, dan lebih besar dari 12% = buruk. Baru-baru ini, kami telah disempurnakan tingkat untuk 0-0,1% sangat baik, 0,1-1% = baik, 1-2,5% = diterima, 2,5-5% = miskin, 5% -12% = sangat miskin, dan lebih besar dari 12% = buruk. Mengubah batas mencerminkan perubahan dalam penekanan kami, yaitu pada tahun 1995 kami terutama peduli dengan email dan ftp. Kutipan dari Vern Paxson meringkas perhatian utama pada saat itu: Kebijaksanaan konvensional antara peneliti TCP menyatakan bahwa tingkat kehilangan 5% memiliki efek samping yang signifikan terhadap kinerja TCP, karena akan sangat membatasi ukuran jendela kemacetan dan karenanya transfer rate, sedangkan 3% sering substansial kurang serius. Dengan kata lain, perilaku kompleks hasil Internet perubahan yang signifikan ketika packet loss naik di atas 3%. Pada tahun 2000 kami juga prihatin dengan aplikasi X-window, kinerja web, dan paket video conferencing. Pada tahun 2005 kami tertarik persyaratan real-time dari VoIP dan mulai melihat voice over IP. Sebagai aturan, kehilangan paket dalam VoIP (dan VoFi) tidak boleh melebihi 1 persen, yang pada dasarnya berarti satu suara melewatkan setiap tiga menit. Algoritma DSP dapat mengimbangi hingga 30 ms data yang hilang; lebih dari ini, dan audio hilang akan terlihat untuk pendengar. The Automotive Jaringan eXchange (ANX) menetapkan ambang batas untuk tingkat packet loss (lihat ANX / Auto Linx Metrik ) menjadi kurang dari 0,1%.
ITU TIPHON kelompok kerja (lihat aspek Jenderal Quality of Service (QOS) , DTR / TIPHON-05001 V1.2.5 (1998-1909) Laporan teknis) juga telah mendefinisikan <3% packet loss sebagai baik,> 15% untuk menengah degradasi, dan 25% untuk degradasi miskin, untuk telepon Internet. Hal ini sangat sulit untuk memberikan nilai tunggal di bawah ini yang packet loss memberikan memuaskan / diterima / kualitas baik suara interaktif. Ada banyak variabel lain yang terlibat termasuk: delay, jitter, Packet Loss Penyembunyian (PLC), apakah kerugian yang acak atau bursty, algoritma kompresi (compression berat menggunakan bandwidth kurang tapi ada lebih kepekaan terhadap packet loss karena banyak data yang terkandung / hilang dalam satu paket). Lihat misalnya Laporan dari 1 ETSI VoIP Pidato Uji Kualitas acara , 21-18 Maret 2001, atau Pidato Pengolahan, Transmisi dan Aspek Kualitas (STQ); Laporan Uji anonim dari 2 Pidato Uji Kualitas Kegiatan 2002 ETSI TR 102 251 v1.1.1 (2003-10) atau laporan Ringkasan ETSI 3 Pidato Uji Kualitas Event, Percakapan Pidato Kualitas VoIP Gateway dan IP Telephony .
Jonathan Rosenberg dari Lucent Technology dan Columbia University di G.729 Kesalahan Pemulihan Internet Telephony disajikan pada VON Conference 9/1997 memberi tabel berikut yang menunjukkan hubungan antara Mean Opinion Score (MOS) dan paket berturut-turut hilang.
| frame berturut-turut hilang | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| MOS | 4.2 | 3.2 | 2.4 | 2.1 | 1.7 |
dimana:
| penilaian | pidato Kualitas | Tingkat distorsi |
|---|---|---|
| 5 | unggul | Tak kelihatan |
| 4 | Baik | Hanya jelas, tidak mengganggu |
| 3 | Adil | Jelas, sedikit mengganggu |
| 2 | Miskin | Mengganggu tapi tidak objectionale |
| 1 | tidak memuaskan | Sangat menjengkelkan, pantas |
Jika paket VoIP ditempatkan terpisah oleh 20msec kemudian 10% loss (dengan asumsi distribusi acak kerugian) adalah setara dengan melihat 2 frame berturut-turut kehilangan sekitar setiap 2 detik, sementara 2,5% kerugian setara dengan 2 frame berturut-turut yang hilang setiap 30 detik.
Jadi kami menetapkan "Acceptable" packet loss di <2,5%. Kertas Pengukuran Kinerja dan Analisis lalu lintas H.323 memberikan berikut untuk VoIP (H.323): Rugi = 0% -0,5% Baik, = 0,5% -1,5% diterima dan> 1,5% = miskin.
Ambang batas atas mengasumsikan distribusi packet loss datar acak. Namun, seringkali kerugian datang dalam semburan. Dalam rangka untuk mengukur packet loss berturut-turut kami telah digunakan, antara lain, yang Conditional Loss Probability (CLP) didefinisikan dalam karakteristik End-to-end Packet Delay dan Loss di internet oleh J. Bolot dalam Journal of Kecepatan Tinggi Networks, vol 2, no. 3 pp 305-323 Desember 1993 (juga tersedia di web ). Pada dasarnya CLP adalah probablility bahwa jika satu paket hilang paket berikut juga hilang. Lebih formal Conditional_loss_probability = Probabilitas (loss (packet n + 1) = true | loss (packet n) = true) . Penyebab semburan tersebut termasuk waktu konvergensi diperlukan setelah perubahan routing (10s untuk 100-detik), kerugian dan pemulihan sync di jaringan DSL (10-20 detik), dan jembatan yang membentang pohon re-konfigurasi (~ 30 detik). Lebih lanjut tentang dampak packet loss bursty dapat ditemukan di Pidato Kualitas Dampak sembarang vs bursty kerugian Packet oleh C. Dvorak, dokumen ITU-T internal. Makalah ini menunjukkan bahwa sedangkan untuk kerugian random drop off di MOS adalah linear dengan% packet loss, kerugian bursty jatuh off jauh lebih cepat. Juga lihat Packet Loss burstiness . Drop off di MOS adalah dari 5 sampai 3,25 untuk perubahan packet loss dari 0 ke 1% dan kemudian itu adalah linear jatuh ke MOS sekitar 2,5 oleh hilangnya 5%.
Upaya pemantauan lain dapat memilih ambang yang berbeda mungkin karena mereka prihatin dengan aplikasi yang berbeda. Halaman lalu lintas MCI berlabel link hijau jika mereka memiliki packet loss <5%, merah jika> 10% dan oranye di antara. Internet Weather Report kita berwarna <kehilangan 6% sebagai hijau dan> 12% merah, dan oranye sebaliknya. Jadi mereka berdua lebih pemaaf daripada kita atau atau setidaknya memiliki kurang rincian. Gary Norton di Jaringan Dunia Desember 2000 (p 40), mengatakan "Jika lebih dari 98% dari paket yang dikirim, pengguna harus mengalami hanya waktu respon sedikit terdegradasi, dan sesi seharusnya tidak waktu keluar".
Gambar di bawah menunjukkan distribusi frekuensi untuk packet loss bulanan rata-rata sekitar 70 situs dilihat dari SLAC antara Januari 1995 dan November 1997. 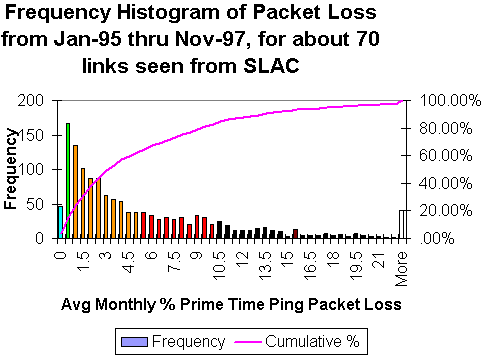
Karena jumlah kompresi yang tinggi dan prediksi gerak-kompensasi dimanfaatkan oleh codec video TelePresence, bahkan sejumlah kecil dari packet loss dapat mengakibatkan degradasi terlihat dari kualitas video. The SLA untuk paket sasaran kerugian bagi Cisco TelePresence harus di bawah 0,05 persen pada jaringan.
Untuk kontrol haptic real time dan umpan balik untuk operasi medis, peneliti Stanford menemukan bahwa kerugian itu bukan faktor dan kerugian hingga 10% kritis bisa ditoleransi.
Namun untuk kinerja tinggi data throughput jarak jauh (tinggi RTT), seperti yang dapat dilihat pada artikel ESNet pada Packet Loss , kerugian sesedikit 0,0046% (1 packet loss di 22.000) dari 10Gbps link dengan MTU set di 9000Bytes (yang dampak lebih besar dengan standar MTU untuk 1500Bytes) hasil faktor dari 10 penurunan throughput untuk RTT> 10msec.
Naik opelet
ITU TIPHON kelompok kerja (lihat aspek Jenderal Quality of Service (QoS) DTR / TIPHON-05001 V1.2.5 (1998-1909) laporan teknis) mendefinisikan empat kategori degradasi jaringan berdasarkan satu arah jitter. Ini adalah:
| kategori degradasi | puncak jitter |
|---|---|
| Sempurna | 0 msec. |
| Baik | 75 msec. |
| Medium | 125 msec. |
| Miskin | 225 msec. |
Kami sedang menyelidiki bagaimana berhubungan satu arah ambang jitter ke ping (pulang-pergi atau dua arah) pengukuran jitter. Kami menggunakan Surveyor satu arah pengukuran delay (lihat di bawah) dan mengukur IQRs dari satu arah delay ( j a => b dan j b => a , dimana subscript a => b menunjukkan node pemantauan di suatu dan pemantauan node remote b ) dan antar delay perbedaan ( J a => b dan J b => a ). Kemudian kita tambahkan dua satu penundaan jalan bagi perangko waktu setara bersama-sama dan menurunkan IQRs untuk round trip delay ( j a <=> b ) dan paket antar delay perbedaan ( J a <=> b ). Melihat sebuah Perbandingan satu dan dua arah jitter orang dapat melihat bahwa distribusi tidak didistribusikan Gaussianly (menjadi lebih tajam dan belum dengan ekor yang lebih luas), jitter diukur dalam satu arah bisa sangat berbeda dari yang diukur dalam arah lain dan untuk ini huruf pendekatan di atas untuk perjalanan pulang-IQR bekerja dengan baik (dalam dua perjanjian persen).
Web browsing dan email cukup tahan terhadap jitter, tetapi setiap jenis media streaming (voice, video, musik) cukup suceptible untuk Jitter. Jitter adalah gejala bahwa ada kemacetan, atau tidak cukup bandwidth untuk menangani lalu lintas.
jitter menentukan panjang buffer VoIP codec playout untuk mencegah over atau under-aliran. Tujuan bisa menentukan yang mengatakan 95% dari delay variasi harus berada dalam interval [-30msec, + 30msec].
Untuk real-time multimedia (H.323) Pengukuran Kinerja dan Analisis H.323 Lalu Lintas memberikan untuk salah satu cara: jitter = 0-20ms = Baik, jitter = 20-50ms = diterima,> 50ms = miskin. Kami mengukur round-trip jitter yang kira-kira dua kali salah satu cara jitter.
Untuk kontrol haptic real time dan umpan balik untuk operasi medis, peneliti Stanford menemukan bahwa jitter adalah kritis dan kegelisahan dari <1msec yang diperlukan.
Throughput
persyaratan kinerja (dari AT & T)
- 768k - 1.5Mbps: berbagi foto, men-download musik, email, web surfing.
- 3.0Mbps - 6.0Mbps - video streaming, game online, jaringan rumah.
- > 6Mbps - hosting website, menonton TV online, men-download film.
Berikut adalah beberapa lebih pedoman:
- Berikut ini adalah dari Pertimbangan Desain untuk Cisco Telepresence lebih Arsitektur PIN . Bandwidth dimanfaatkan per Cisco TelePresence endpoint bervariasi berdasarkan faktor-faktor yang meliputi model dikerahkan, resolusi video yang diinginkan, interoperabilitas dengan sistem konferensi video lawas, dan apakah input video tambahan kecepatan tinggi atau rendah dikerahkan untuk kamera dokumen atau slide presentasi. Misalnya, ketika deploying resolusi video 1080p terbaik dengan kecepatan tinggi input video tambahan dan interoperabilitas, kebutuhan bandwidth dapat setinggi 20,4 Mbps untuk CTS-3200 dan CTS-3000, atau 10,8 Mbps untuk CTS-1000 dan CTS-500 .
- FCC Broadband Gratis
Pemanfaatan
Link pemanfaatan dapat dibaca dari router melalui SNMP MIB (dengan asumsi satu memiliki otorisasi untuk membaca informasi tersebut). "Pada sekitar 90 pemanfaatan% jaringan yang khas akan membuang 2% dari paket, tapi ini bervariasi. Link bandwidth rendah memiliki kurang luasnya untuk menangani semburan, sering membuang paket di hanya 80 pemanfaatan% ... Sebuah cek kesehatan jaringan lengkap harus mengukur . kapasitas link mingguan Berikut adalah kode warna yang disarankan:
- RED: Packet membuang> 2%, menyebarkan ada aplikasi baru.
- AMBER: Pemanfaatan> 60%. Pertimbangkan upgrade jaringan.
- GREEN: Pemanfaatan <60%. Diterima untuk penyebaran aplikasi baru. "
Kecepatan tinggi perlambatan , Gary Norton, Jaringan Magazine, 2000. Desember di atas tidak menunjukkan selama periode apa pemanfaatannya diukur. Di tempat lain dalam artikel Norton katanya "Kapasitas jaringan ... dihitung sebagai rata-rata dari jam busiets lebih dari 5 hari kerja".
"Teori Antrian menunjukkan bahwa variasi dalam waktu round trip, o , bervariasi sebanding dengan 1 / (1-L) di mana L adalah beban jaringan saat ini, 0 <= L <= 1 . Jika internet berjalan pada kapasitas 50%, kami berharap round trip delay bervariasi dengan faktor + - 2o , atau 4. Ketika beban mencapai 80%, kami berharap variasi dari 10. " Internetworking dengan TCP / IP, Prinsip, Protokol dan Arsitektur , Douglas Comer, Prentice Hall. Hal ini menunjukkan salah satu mungkin bisa mendapatkan ukuran pemanfaatan dengan melihat variabilitas dalam RTT. Kami belum divalidasi saran ini pada saat ini.
reachability
Bellcore Generic Requirement 929 (GR-929-CORE Keandalan dan Pengukuran Kualitas Sistem Telekomunikasi (RQMS) (Wireline) , secara aktif digunakan oleh pemasok dan penyedia layanan sebagai dasar pelaporan pemasok kinerja kuartalan diukur terhadap tujuan. Setiap tahun, setelah publikasi edisi terbaru dari GR-929-CORE, tujuan kinerja direvisi tersebut dilaksanakan) menunjukkan bahwa inti dari jaringan telepon bertujuan untuk ketersediaan 99,999%, itu berarti kurang dari 5,3 menit downtime per tahun. Seperti ditulis pengukuran tidak termasuk pemadaman kurang dari 30 detik. Ini ditujukan untuk switch digital PSTN saat ini (seperti Electronic Switching System 5 (5ESS) dan Nortel DMS250), menggunakan todays teknologi voice-over-ATM. Sebuah sistem switching publik diperlukan untuk membatasi waktu pemadaman total selama periode 40-tahun sampai kurang dari dua jam, atau kurang dari tiga menit per tahun, sejumlah setara dengan ketersediaan 99,99943%. Dengan konvergensi data dan suara, ini berarti bahwa jaringan data yang akan membawa beberapa layanan termasuk suara harus mulai dari ketersediaan yang sama atau lebih baik atau pengguna akhir akan kesal dan frustrasi.
Tingkat ketersediaan sering dilemparkan ke dalam Service Level Agreements. Tabel di bawah ini (berdasarkan Cahners In-Stat survei dari sampel Application Service Provider (ASP)) menunjukkan tingkat ketersediaan yang ditawarkan oleh ASP dan tingkat dipilih oleh pelanggan.
| tingkat ditawarkan | Dipilih oleh pelanggan | |
|---|---|---|
| Kurang dari 99% | 26% | 19% |
| ketersediaan 99% | 39% | 24% |
| ketersediaan 99,9% | 24% | 15% |
| ketersediaan 99,99% | 15% | 5% |
| ketersediaan 99,999% | 18% | 5% |
| ketersediaan lebih dari 99,999% | 13% | 15% |
| Tidak tahu | 13% | 18% |
| Rata-rata tertimbang dari ketersediaan ditawarkan | 99,5% | 99,4% |
Untuk informasi lebih lanjut tentang availabilty dll melihat: Cisco White Paper on Always-On Ketersediaan untuk Multiservice Pembawa Networks untuk bagaimana Cisco berjuang untuk ketersediaan tinggi pada jaringan data; A Modern Taksonomi Tinggi Ketersediaan ; dan IETF dokumen RFC 2498: IPPM Metrik untuk Mengukur Konektivitas .
directivity
Batas-batas theorteical pada Directivity adalah bahwa hal itu harus ≥ 0 dan ≤ 1. Nilai 1 menunjukkan rute yang adalah rute lingkaran besar dan satu-satunya keterlambatan ini disebabkan oleh kecepatan cahaya dalam serat atau elektron dalam tembaga. Nilai> 1 biasanya menunjukkan sumber atau tujuan atau keduanya memiliki lokasi yang salah dan membuat Directivity diagnostik yang berguna untuk lokasi tuan rumah. Nilai-nilai khas dari Directivity antara penelitian dan situs pendidikan di AS, Kanada, Eropa, Asia Timur, dan Australia / Selandia Baru bervariasi 0,15-0,75 dengan rata-rata sekitar 0,4. Hal ini sesuai dengan sekitar 4 kali lebih lambat dari kecepatan cahaya dalam ruang hampa. Nilai-nilai rendah Directivity biasanya berarti rute yang sangat tidak langsung, atau satelit atau koneksi yang lambat (misalnya nirkabel)
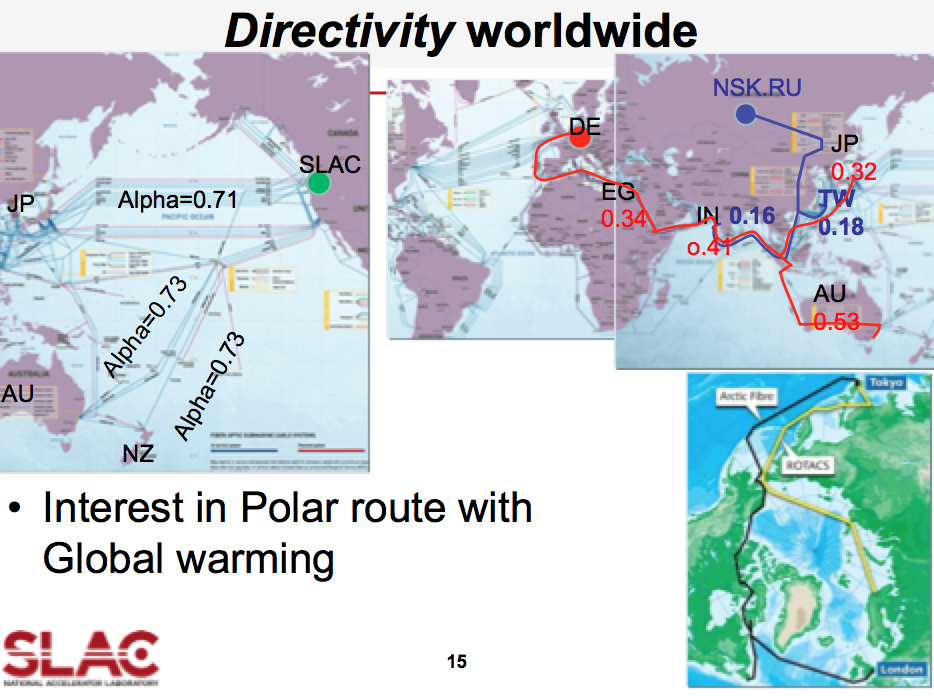
Pengelompokan
Karena jumlah pasangan tuan rumah sedang dipantau meningkat menjadi semakin perlu untuk menggabungkan data ke dalam kelompok yang mewakili bidang minat. Kami telah menemukan berikut pengelompokan kategori untuk menjadi berguna:
- oleh daerah (misalnya N. America, W. Eropa, Jepang, Asia, negara, top level domain);
- dengan pemisahan tuan rumah pasangan (misalnya link trans-samudera, link antarbenua, Internet eXchange Points );
- Jaringan Service Provider backbone bahwa situs remote terhubung ke (misalnya ESNet , Internet 2 , DANTE ...);
- afiliasi kepentingan umum (misalnya XIWT , HENP , percobaan kolaborasi seperti Babar , Eropa atau DOE National Laboratories, kepentingan Program ESNet, perfSONAR )
- oleh situs monitoring;
- salah satu situs remote dilihat dari banyak situs pemantauan. Kita harus mampu untuk memilih thr pengelompokan dengan memantau situs dan oleh situs remote. Juga kita perlu kemampuan untuk mencakup semua anggota kelompok, untuk bergabung dengan kelompok dan untuk mengecualikan anggota grup.
Beberapa contoh berapa banyak ~ pasangan 1100 Pinger memonitor-host remote-situs yang di kelompok area global dan kelompok afinitas dapat ditemukan di pasangan Pinger pengelompokan distribusi .
Pada saat yang sama sangat penting untuk memilih situs remote dan host-pasangan dengan hati-hati sehingga mereka mewakili informasi satu berharap untuk mencari tahu. Oleh karena itu kami telah memilih satu set sekitar 50 "Tempat Beacon" yang dipantau oleh semua situs pemantauan dan yang mewakili berbagai kelompok afinitas kita tertarik. Contoh kali grafik menunjukkan ping respon untuk kelompok situs yang terlihat di bawah :
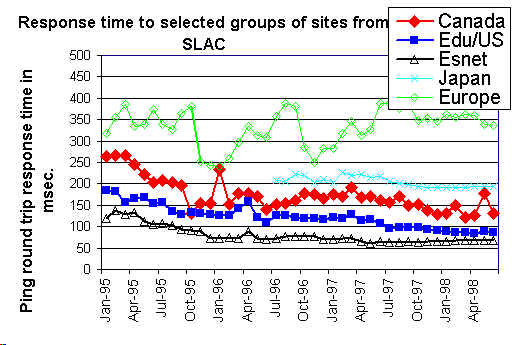
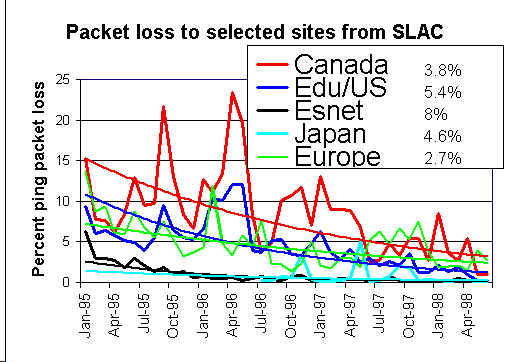
persentase ditampilkan di sebelah kanan legenda grafik paket hilang adalah perbaikan (pengurangan packet loss) per bulan untuk garis tren eksponensial cocok dengan data packet loss. Perhatikan bahwa peningkatan / bulan 5% setara dengan 44% peningkatan / tahun (misalnya 10% kerugian akan turun menjadi 5,6% dalam setahun).
One Way Pengukuran
SLAC juga berkolaborasi dalam perfSONAR proyek untuk membuat salah satu cara delay dan loss pengukuran antara situs perfSONAR. Setiap situs perfSONAT memiliki titik pengukuran yang terdiri dari internet komputer yang terhubung dengan receiver GPS. Hal ini memungkinkan waktu disinkronisasi akurat stamping paket yang memungkinkan pengukuran delay satu cara. Perkiraan delay yang dihasilkan lebih rinci dari pinger dan memperjelas asimetri pada jalur Internet dalam dua arah. Untuk lebih lanjut tentang membandingkan dua metode melihat Perbandingan Pinger dan Surveyor .
RIPE juga memiliki Lalu Lintas Uji proyek untuk membuat pengukuran independen parameter konektivitas, seperti keterlambatan dan routing-vektor di Internet. Sebuah host RIPE dipasang di SLAC.
The NLANR Active Pengukuran Program (AMP) untuk penerima beasiswa HPC dimaksudkan untuk meningkatkan pemahaman tentang bagaimana tinggi kinerja jaringan berkinerja seperti yang terlihat oleh situs yang berpartisipasi dan pengguna, dan untuk membantu dalam diagnosis masalah bagi kedua pengguna jaringan dan penyedia nya. Mereka memasang rak mountable mesin FreeBSD di situs dan membuat full mesh pengukuran ping aktif antara mesin mereka, dengan ping yang diluncurkan pada sekitar 1 menit interval. Mesin AMP dipasang di SLAC.
Perbandingan yang lebih rinci Surveyor, RIPE, pinger dan AMP dapat ditemukan di Perbandingan beberapa Internet End-to-end proyek Pengukuran Kinerja Aktif .
SLAC juga Nimi (National Measurement Internet Infrastructure) situs. Proyek ini dapat dianggap sebagai pelengkap untuk proyek Surveyor, dalam hal itu (Nimi) lebih difokuskan pada penyediaan infrastruktur untuk mendukung berbagai metodologi pengukuran seperti salah satu cara ping, Treno, traceroute, Pinger dll
Waikato University di Selandia Baru juga menyebarkan Linux host masing-masing dengan receiver GPS dan melakukan pengukuran delay satu cara. Untuk lebih lanjut tentang melihat Waikato ini ini Temuan Keterlambatan halaman. Tidak seperti AMP, proyek RIPE dan Surveyor, proyek Waikato membuat pengukuran pasif, lalu lintas normal antara pasangan yang ada, menggunakan CRC paket berdasarkan tanda tangan untuk mengidentifikasi paket yang tercatat di 2 ujung.
The sengatan alat ukur jaringan berbasis TCP-mampu secara aktif mengukur packet loss di kedua maju dan mundur jalur antara pasangan host. Ini memiliki keuntungan tidak membutuhkan GPS, dan tidak tunduk pada ICMP tingkat membatasi atau memblokir (menurut studi ISI ~ 61% dari tuan rumah di Internet tidak repond ping), namun itu memerlukan modifikasi kernel kecil .
Jika salah satu cara delay ( D ) dikenal untuk kedua arah dari pasangan Internet node ( a, b ), maka round trip delay R dapat dihitung sebagai berikut:
R = D a => b + D b => a
di mana D a => b adalah salah satu cara delay diukur dari node ke node b dan sebaliknya.
Kedua cara packet loss P dapat diturunkan dari kerugian satu cara ( p ) sebagai berikut:
P = p a => b + p b => a - p a => b * p b => a
di mana p a => b adalah salah satu cara packet loss dari node a ke b dan sebaliknya.
Ada beberapa RFC IETF terkait dengan mengukur salah satu cara delay dan loss serta round trip delay metrik .
traceroute
Alat lain yang sangat ampuh untuk mendiagnosis masalah jaringan traceroute . Hal ini memungkinkan seseorang untuk menemukan jumlah hop ke situs remote dan seberapa baik dengan bekerja.John MacAllister di Oxford dikembangkan Traceping Route Pemantauan Statistik berdasarkan standar traceroute dan ping utilitas. Statistik yang dikumpulkan secara berkala untuk periode 24-jam dan menyediakan informasi tentang konfigurasi routing, kualitas rute dan stabilitas rute.
TRIUMF juga memiliki sangat bagus Traceroute Peta alat yang menunjukkan peta ke banyak situs lain rute dari TRIUMF. Kami mencari cara untuk memberikan penyederhanaan peta tersebut menggunakan Sistem Otonomi (AS) melewati daripada router.
Satu juga dapat merencanakan FTP Throughput vs hop traceroute serta respon ping dan packet loss untuk mencari korelasi.
Banyak situs yang muncul yang menjalankan server traceroute (yang kode sumber (di Perl) tersedia) yang membantu dalam debugging dan dalam memahami topologi internet.
Beberapa situs menyediakan akses ke utilitas jaringan seperti nslookup untuk memungkinkan seseorang untuk mengetahui lebih lanjut tentang node tertentu. Beberapa contoh adalah SLAC dan TRIUMF .
Dampak Routing di Internet Kinerja End-to-end
Glosarium
- DSCP Differentiated Services codepoint. Layanan Differentiated codepoint adalah 6 bit di bidang header IP yang digunakan dalam memilih per-hop-perilaku paket. 6 bit untuk DSCP dan 2 bit yang tidak digunakan dimaksudkan untuk menggantikan definisi yang ada dari oktet IPv4 KL, lihat RFC 2474 untuk rincian lebih lanjut.
- MTU Transfer Unit Maksimum. Unit transfer maksimum adalah ukuran terbesar dari IP datagram yang dapat ditransfer menggunakan koneksi data link tertentu.
- MSS Ukuran Segmen Maksimum. MTU-40.
- QBSS QBone Scavenger Services. QBone Scavenger Services adalah kelas tambahan layanan terbaik-usaha. Sejumlah kecil kapasitas jaringan dialokasikan (dalam cara yang non-rigid) untuk layanan ini; bila kapasitas standar terbaik-upaya yang kurang dimanfaatkan, QBSS dapat memperluas untuk mengkonsumsi kapasitas yang tidak terpakai.
- Menerima Window (Rwin) Ukuran buffer TCP, jumlah paket mesin Anda akan mengirimkan tanpa menerima ACK.
Informasi lebih lanjut
- SLAC Pembicaraan dan Makalah tentang Jaringan Monitoring .
- Jaringan Monitoring Alat
- Pemantauan ICFA-NTF Kelompok Kerja menyediakan banyak informasi yang berguna hasil end-to-end monitoring internet.
- Mengapa hal Latency untuk Mobile Backhaul .
- Panduan Jaringan Penelitian Pengguna untuk Kinerja: Basis Pengetahuan dari Tim Peningkatan Response Geant2 Kinerja.
- Jaringan Manajemen Protokol dari Realtime Publishers.
- Kelompok Kerja Metrik Caida .
- Manajemen jaringan Tutorial .
- Referensi tentang Pengelolaan Jaringan .
- Persyaratan Pemantauan Jaringan untuk Grid dari EuroGrid WP7 memberikan gambaran yang menarik dari metode untuk memantau dll
cron A cronjob memanggil script yang sesuai. Di SLAC cronjob ini berada di [email protected]/.trs/crontab. Untuk PingER1 script disebut timeping.pl, untuk PingER2 itu disebut pinger2.pl . Di SLAC skrip Pinger semua dalam Perldan kecuali dinyatakan lain yang ditemukan di jalan / afs / SLAC / paket / netmon / pinger /
mengumpulkan Data tersebut dikumpulkan di SLAC oleh skrip getdata.pl yang menggunakan Lynx untuk mendapatkan data dari yang CGI ping_data.pl skrip di setiap situs monitoring. Getdata.pl disebut setiap hari untuk mengumpulkan data ke SLAC situs pengarsipan. Hal ini disebut dari cronjob sama seperti panggilan timeping.pl (lihat di atas).
Analisis Informasi tentang rantai analisis script dapat ditemukan di: "Mengembalikan Data Historis" yang menjelaskan rantai analisis secara keseluruhan.
pingtable Mekanisme pelaporan utama adalah melalui pingtable.pl script yang di SLAC disimpan dalam Pinger CGI path / afs / SLAC / g / www / cgi-wrap-bin / net / offsite_mon / pinghistory /.
